 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Differentially Private Regret Minimization in Reinforcement Learning
Paper and Code
Oct 15, 2020
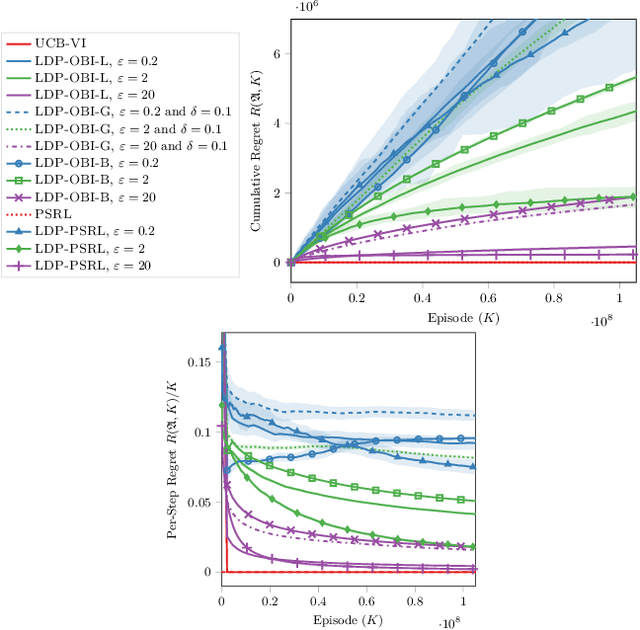
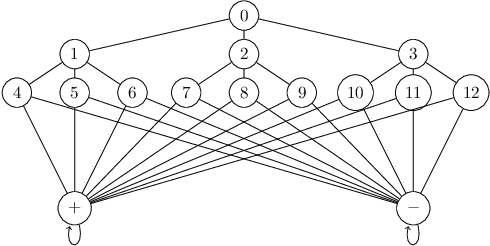
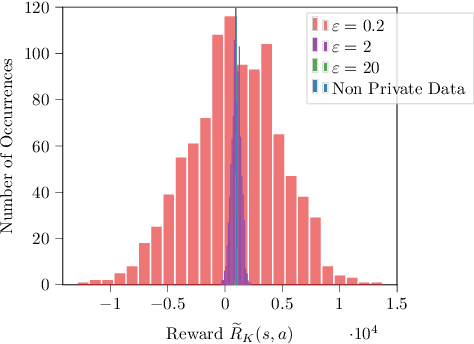
Reinforcement learning algorithms are widely used in domains where it is desirable to provide a personalized service. In these domains it is common that user data contains sensitive information that needs to be protected from third parties. Motivated by this, we study privacy in the context of finite-horizon Markov Decision Processes (MDPs) by requiring information to be obfuscated on the user side. We formulate this notion of privacy for RL by leveraging the local differential privacy (LDP) framework. We present an optimistic algorithm that simultaneously satisfies LDP requirements, and achieves sublinear regret. We also establish a lower bound for regret minimization in finite-horizon MDPs with LDP guarantees. These results show that while LDP is appealing in practical applications, the setting is inherently more complex. In particular, our results demonstrate that the cost of privacy is multiplicative when compared to non-private settings.