 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Compressed Video Stream Learning for Generic Event Boundary Detection
Paper and Code

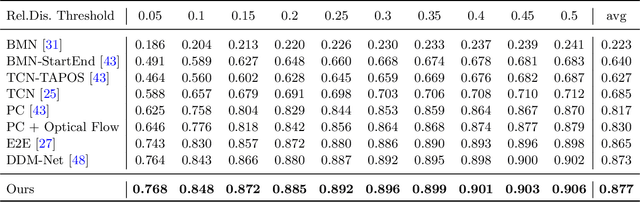
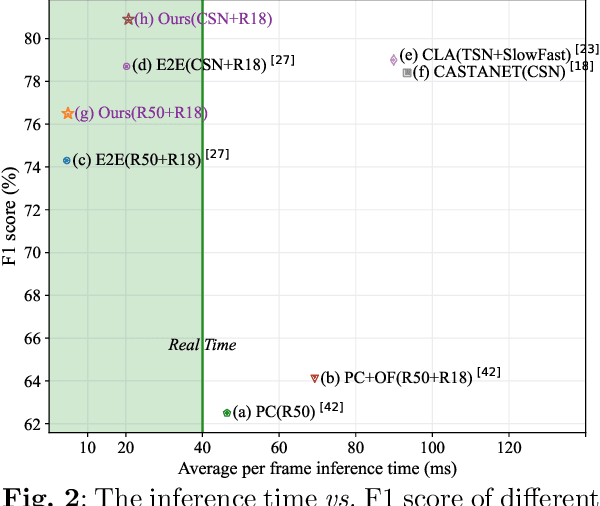
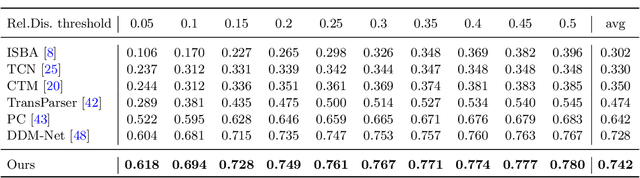
Generic event boundary detection aims to localize the generic, taxonomy-free event boundaries that segment videos into chunks. Existing methods typically require video frames to be decoded before feeding into the network, which contains significant spatio-temporal redundancy and demands considerable computational power and storage space. To remedy these issues, we propose a novel compressed video representation learning method for event boundary detection that is fully end-to-end leveraging rich information in the compressed domain, i.e., RGB, motion vectors, residuals, and the internal group of pictures (GOP) structure, without fully decoding the video. Specifically, we use lightweight ConvNets to extract features of the P-frames in the GOPs and spatial-channel attention module (SCAM) is designed to refine the feature representations of the P-frames based on the compressed information with bidirectional information flow. To learn a suitable representation for boundary detection, we construct the local frames bag for each candidate frame and use the long short-term memory (LSTM) module to capture temporal relationships. We then compute frame differences with group similarities in the temporal domain. This module is only applied within a local window, which is critical for event boundary detection. Finally a simple classifier is used to determine the event boundaries of video sequences based on the learned feature representation. To remedy the ambiguities of annotations and speed up the training process, we use the Gaussian kernel to preprocess the ground-truth event boundaries. Extensive experiments conducted on the Kinetics-GEBD and TAPOS datasets demonstrate that the proposed method achieves considerable improvements compared to previous end-to-end approach while running at the same speed. The code is available at https://github.com/GX77/LCVSL.