 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMEC: Learnable Multiplicative Absolute Position Embedding Based Conformer for Speech Recognition
Paper and Code
Dec 05, 2022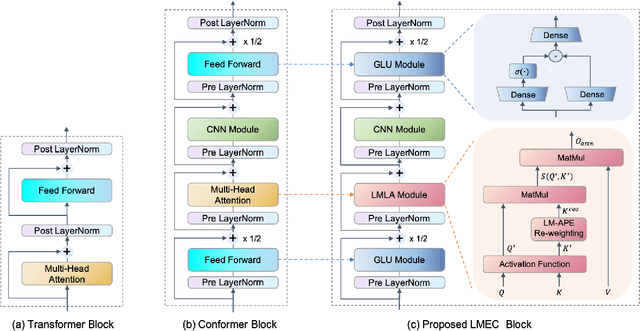
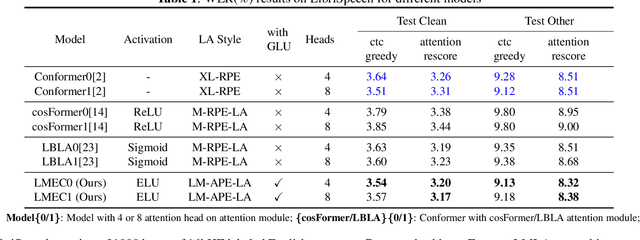
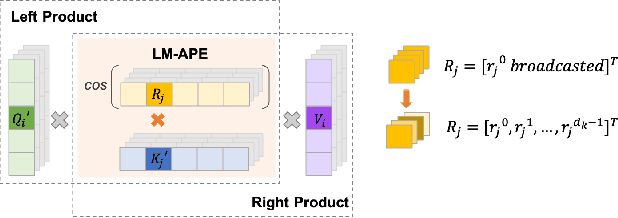
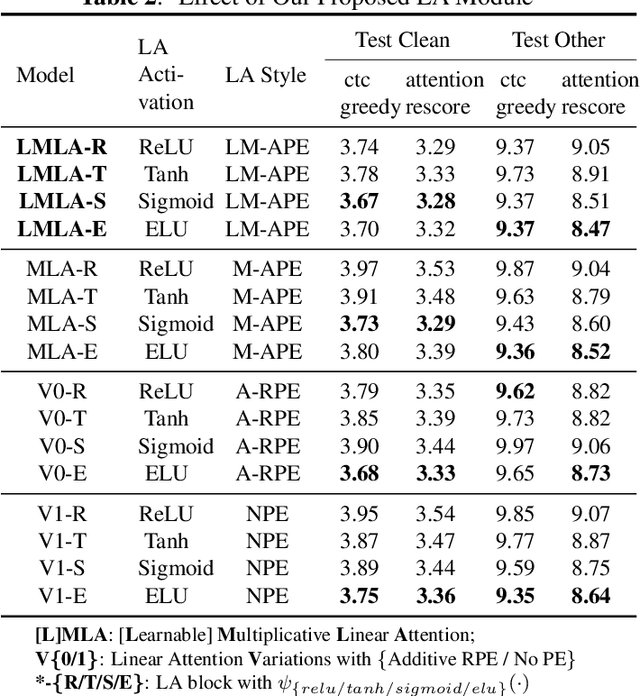
This paper proposes a Learnable Multiplicative absolute position Embedding based Conformer (LMEC). It contains a kernelized linear attention (LA) module called LMLA to solve the time-consuming problem for long sequence speech recognition as well as an alternative to the FFN structure. First, the ELU function is adopted as the kernel function of our proposed LA module. Second, we propose a novel Learnable Multiplicative Absolute Position Embedding (LM-APE) based re-weighting mechanism that can reduce the well-known quadratic temporal-space complexity of softmax self-attention. Third, we use Gated Linear Units (GLU) to substitute the Feed Forward Network (FFN) for better performance. Extensive experiments have been conducted on the public LibriSpeech datasets. Compared to the Conformer model with cosFormer style linear attention, our proposed method can achieve up to 0.63% word-error-rate improvement on test-other and improve the inference speed by up to 13% (left product) and 33% (right product) on the LA module.