 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinguistically Driven Graph Capsule Network for Visual Question Reasoning
Paper and Code
Mar 23, 2020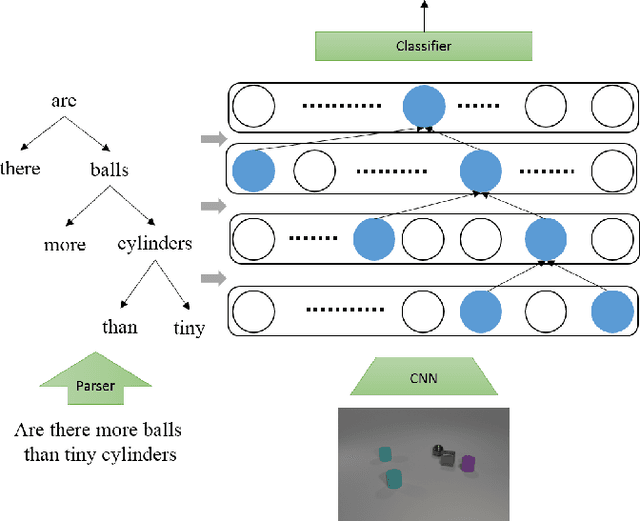
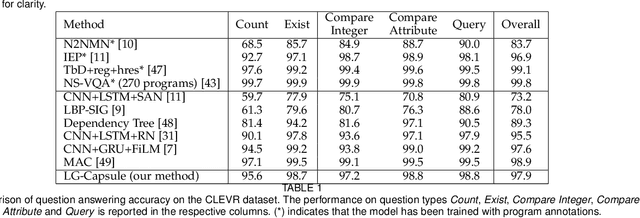
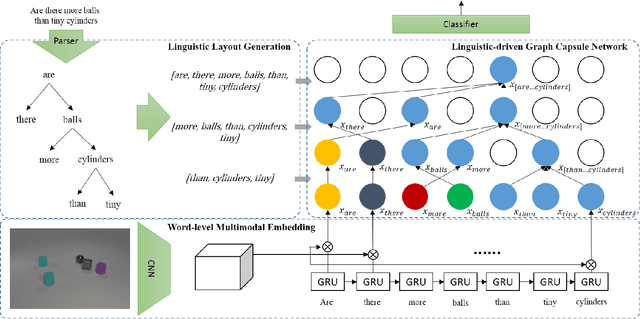

Recently, studies of visual question answering have explored various architectures of end-to-end networks and achieved promising results on both natural and synthetic datasets, which require explicitly compositional reasoning. However, it has been argued that these black-box approaches lack interpretability of results, and thus cannot perform well on generalization tasks due to overfitting the dataset bias. In this work, we aim to combine the benefits of both sides and overcome their limitations to achieve an end-to-end interpretable structural reasoning for general images without the requirement of layout annotations. Inspired by the property of a capsule network that can carve a tree structure inside a regular convolutional neural network (CNN), we propose a hierarchical compositional reasoning model called the "Linguistically driven Graph Capsule Network", where the compositional process is guided by the linguistic parse tree. Specifically, we bind each capsule in the lowest layer to bridge the linguistic embedding of a single word in the original question with visual evidence and then route them to the same capsule if they are siblings in the parse tree. This compositional process is achieved by performing inference on a linguistically driven conditional random field (CRF) and is performed across multiple graph capsule layers, which results in a compositional reasoning process inside a CNN. Experiments on the CLEVR dataset, CLEVR compositional generation test, and FigureQA dataset demonstrate the effectiveness and composition generalization ability of our end-to-end model.