 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Contextual Bandits with Adversarial Corruptions
Paper and Code
Oct 25, 2021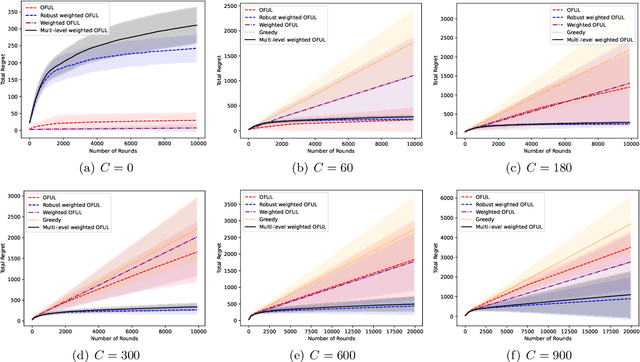
We study the linear contextual bandit problem in the presence of adversarial corruption, where the interaction between the player and a possibly infinite decision set is contaminated by an adversary that can corrupt the reward up to a corruption level $C$ measured by the sum of the largest alteration on rewards in each round. We present a variance-aware algorithm that is adaptive to the level of adversarial contamination $C$. The key algorithmic design includes (1) a multi-level partition scheme of the observed data, (2) a cascade of confidence sets that are adaptive to the level of the corruption, and (3) a variance-aware confidence set construction that can take advantage of low-variance reward. We further prove that the regret of the proposed algorithm is $\tilde{O}(C^2d\sqrt{\sum_{t = 1}^T \sigma_t^2} + C^2R\sqrt{dT})$, where $d$ is the dimension of context vectors, $T$ is the number of rounds, $R$ is the range of noise and $\sigma_t^2,t=1\ldots,T$ are the variances of instantaneous reward. We also prove a gap-dependent regret bound for the proposed algorithm, which is instance-dependent and thus leads to better performance on good practical instances. To the best of our knowledge, this is the first variance-aware corruption-robust algorithm for contextual bandits. Experiments on synthetic data corroborate our theory.