 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexis: An Optimization Framework for Discovering the Hierarchical Structure of Sequential Data
Paper and Code
Jun 11, 2016


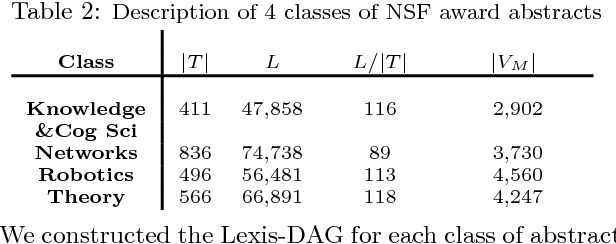
Data represented as strings abounds in biology, linguistics, document mining, web search and many other fields. Such data often have a hierarchical structure, either because they were artificially designed and composed in a hierarchical manner or because there is an underlying evolutionary process that creates repeatedly more complex strings from simpler substrings. We propose a framework, referred to as "Lexis", that produces an optimized hierarchical representation of a given set of "target" strings. The resulting hierarchy, "Lexis-DAG", shows how to construct each target through the concatenation of intermediate substrings, minimizing the total number of such concatenations or DAG edges. The Lexis optimization problem is related to the smallest grammar problem. After we prove its NP-Hardness for two cost formulations, we propose an efficient greedy algorithm for the construction of Lexis-DAGs. We also consider the problem of identifying the set of intermediate nodes (substrings) that collectively form the "core" of a Lexis-DAG, which is important in the analysis of Lexis-DAGs. We show that the Lexis framework can be applied in diverse applications such as optimized synthesis of DNA fragments in genomic libraries, hierarchical structure discovery in protein sequences, dictionary-based text compression, and feature extraction from a set of documents.