Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexical Knowledge Internalization for Neural Dialog Generation
Paper and Code
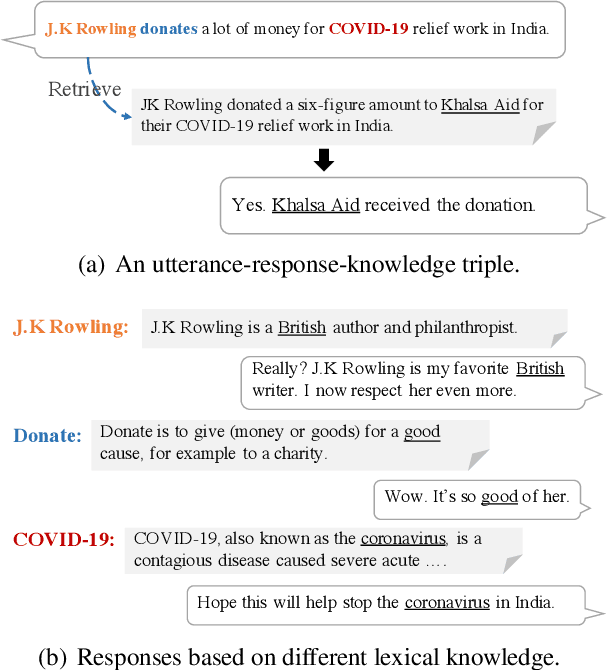
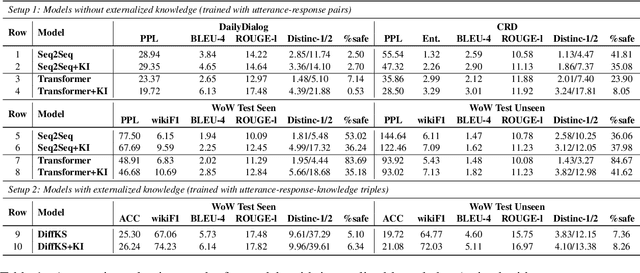


We propose knowledge internalization (KI), which aims to complement the lexical knowledge into neural dialog models. Instead of further conditioning the knowledge-grounded dialog (KGD) models on externally retrieved knowledge, we seek to integrate knowledge about each input token internally into the model's parameters. To tackle the challenge due to the large scale of lexical knowledge, we adopt the contrastive learning approach and create an effective token-level lexical knowledge retriever that requires only weak supervision mined from Wikipedia. We demonstrate the effectiveness and general applicability of our approach on various datasets and diversified model structures.
* To appear at ACL 2022 main conference
View paper on