 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging unsupervised and weakly-supervised data to improve direct speech-to-speech translation
Paper and Code
Mar 24, 2022
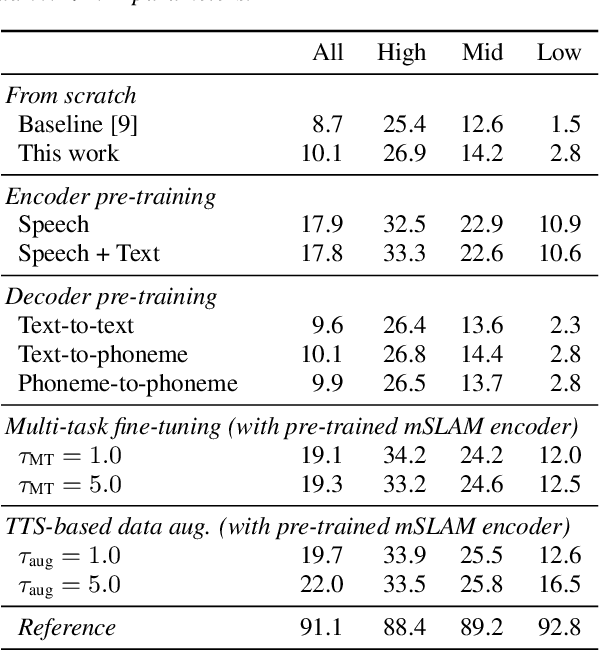
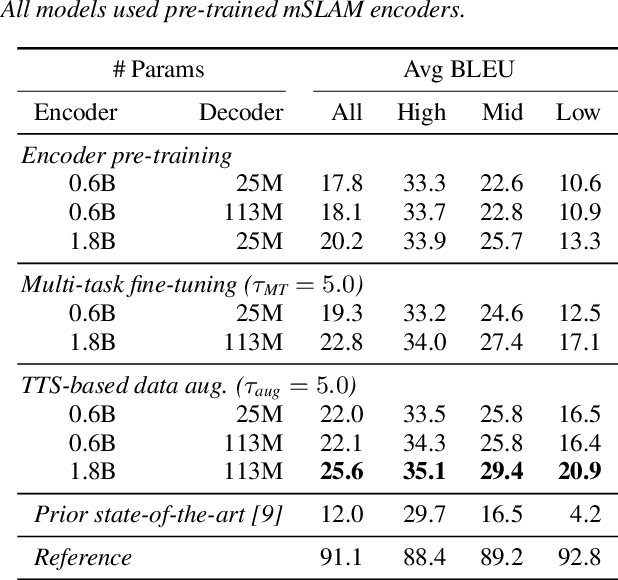
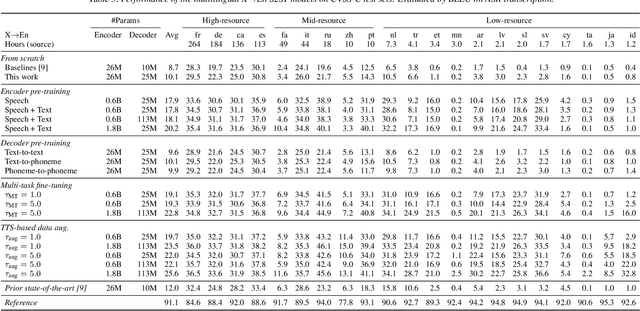
End-to-end speech-to-speech translation (S2ST) without relying on intermediate text representations is a rapidly emerging frontier of research. Recent works have demonstrated that the performance of such direct S2ST systems is approaching that of conventional cascade S2ST when trained on comparable datasets. However, in practice, the performance of direct S2ST is bounded by the availability of paired S2ST training data. In this work, we explore multiple approaches for leveraging much more widely available unsupervised and weakly-supervised speech and text data to improve the performance of direct S2ST based on Translatotron 2. With our most effective approaches, the average translation quality of direct S2ST on 21 language pairs on the CVSS-C corpus is improved by +13.6 BLEU (or +113% relatively), as compared to the previous state-of-the-art trained without additional data. The improvements on low-resource language are even more significant (+398% relatively on average). Our comparative studies suggest future research directions for S2ST and speech representation learning.