 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnt Sparsity for Effective and Interpretable Document Ranking
Paper and Code
Jun 23, 2021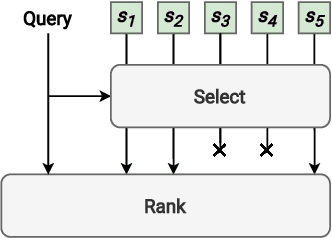
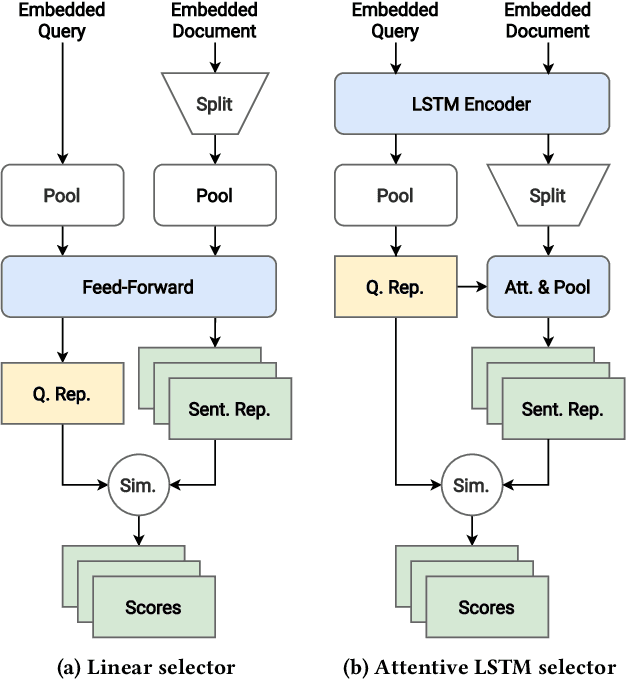
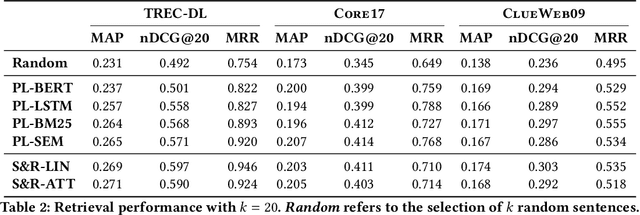
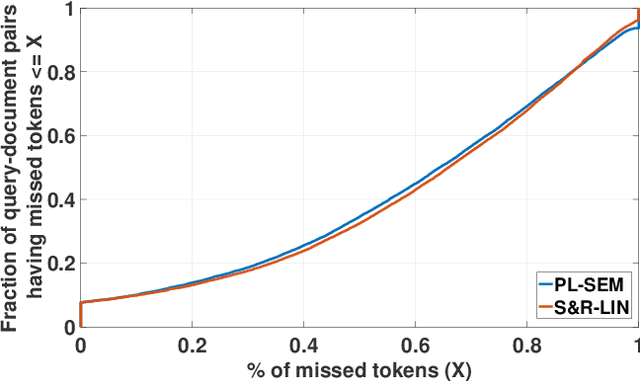
Machine learning models for the ad-hoc retrieval of documents and passages have recently shown impressive improvements due to better language understanding using large pre-trained language models. However, these over-parameterized models are inherently non-interpretable and do not provide any information on the parts of the documents that were used to arrive at a certain prediction. In this paper we introduce the select and rank paradigm for document ranking, where interpretability is explicitly ensured when scoring longer documents. Specifically, we first select sentences in a document based on the input query and then predict the query-document score based only on the selected sentences, acting as an explanation. We treat sentence selection as a latent variable trained jointly with the ranker from the final output. We conduct extensive experiments to demonstrate that our inherently interpretable select-and-rank approach is competitive in comparison to other state-of-the-art methods and sometimes even outperforms them. This is due to our novel end-to-end training approach based on weighted reservoir sampling that manages to train the selector despite the stochastic sentence selection. We also show that our sentence selection approach can be used to provide explanations for models that operate on only parts of the document, such as BERT.