 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Non-Convex Truncated Losses by SGD
Paper and Code
May 21, 2018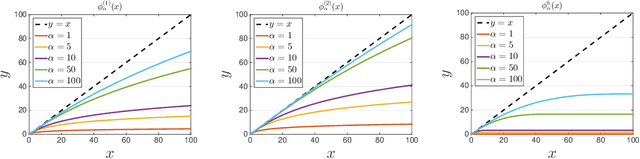

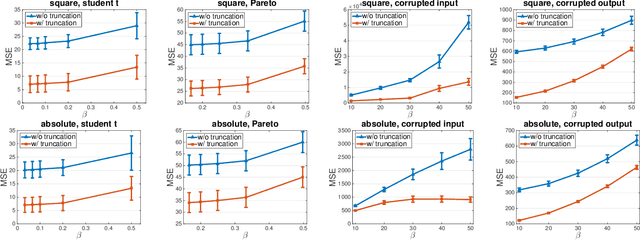
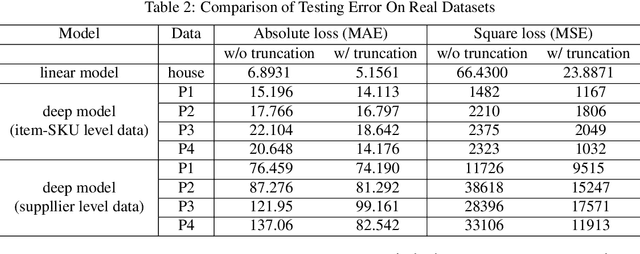
Learning with a {\it convex loss} function has been a dominating paradigm for many years. It remains an interesting question how non-convex loss functions help improve the generalization of learning with broad applicability. In this paper, we study a family of objective functions formed by truncating traditional loss functions, which is applicable to both shallow learning and deep learning. Truncating loss functions has potential to be less vulnerable and more robust to large noise in observations that could be adversarial. More importantly, it is a generic technique without assuming the knowledge of noise distribution. To justify non-convex learning with truncated losses, we establish excess risk bounds of empirical risk minimization based on truncated losses for heavy-tailed output, and statistical error of an approximate stationary point found by stochastic gradient descent (SGD) method. Our experiments for shallow and deep learning for regression with outliers, corrupted data and heavy-tailed noise further justify the proposed method.