 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Visual Features from Large Weakly Supervised Data
Paper and Code
Nov 06, 2015
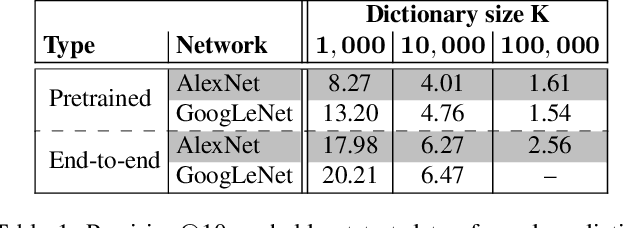
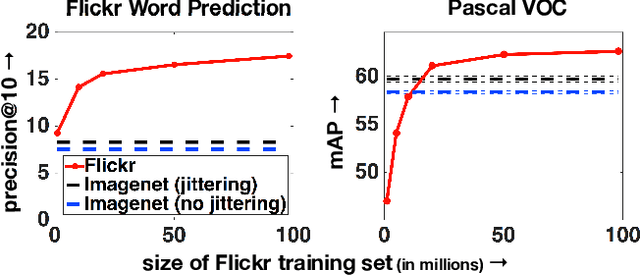

Convolutional networks trained on large supervised dataset produce visual features which form the basis for the state-of-the-art in many computer-vision problems. Further improvements of these visual features will likely require even larger manually labeled data sets, which severely limits the pace at which progress can be made. In this paper, we explore the potential of leveraging massive, weakly-labeled image collections for learning good visual features. We train convolutional networks on a dataset of 100 million Flickr photos and captions, and show that these networks produce features that perform well in a range of vision problems. We also show that the networks appropriately capture word similarity, and learn correspondences between different languages.