 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Ultrasound Rendering from Cross-Sectional Model Slices for Simulated Training
Paper and Code
Jan 20, 2021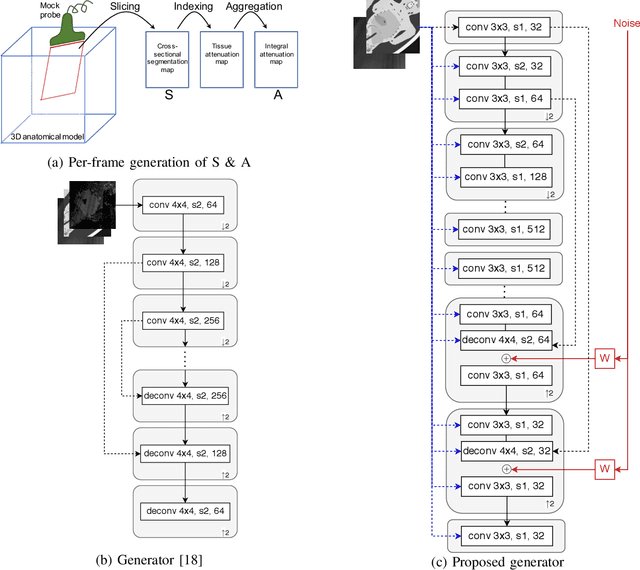

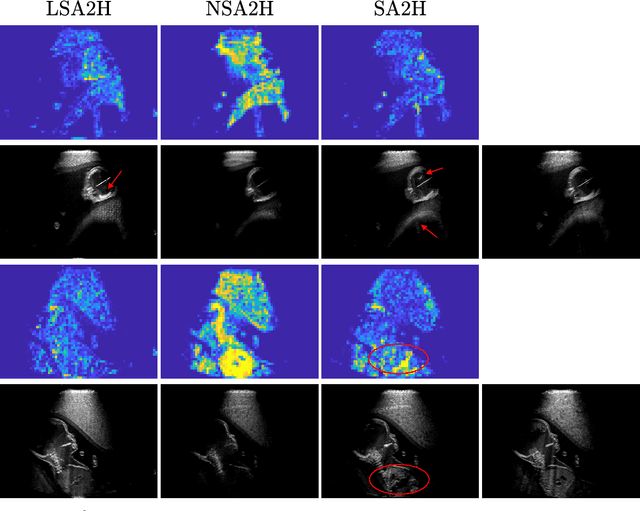
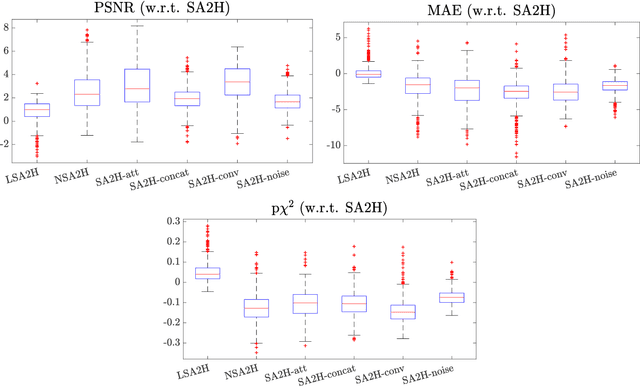
Purpose. Given the high level of expertise required for navigation and interpretation of ultrasound images, computational simulations can facilitate the training of such skills in virtual reality. With ray-tracing based simulations, realistic ultrasound images can be generated. However, due to computational constraints for interactivity, image quality typically needs to be compromised. Methods. We propose herein to bypass any rendering and simulation process at interactive time, by conducting such simulations during a non-time-critical offline stage and then learning image translation from cross-sectional model slices to such simulated frames. We use a generative adversarial framework with a dedicated generator architecture and input feeding scheme, which both substantially improve image quality without increase in network parameters. Integral attenuation maps derived from cross-sectional model slices, texture-friendly strided convolutions, providing stochastic noise and input maps to intermediate layers in order to preserve locality are all shown herein to greatly facilitate such translation task. Results. Given several quality metrics, the proposed method with only tissue maps as input is shown to provide comparable or superior results to a state-of-the-art that uses additional images of low-quality ultrasound renderings. An extensive ablation study shows the need and benefits from the individual contributions utilized in this work, based on qualitative examples and quantitative ultrasound similarity metrics. To that end, a local histogram statistics based error metric is proposed and demonstrated for visualization of local dissimilarities between ultrasound images.