 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Recognize Dialect Features
Paper and Code
Oct 23, 2020
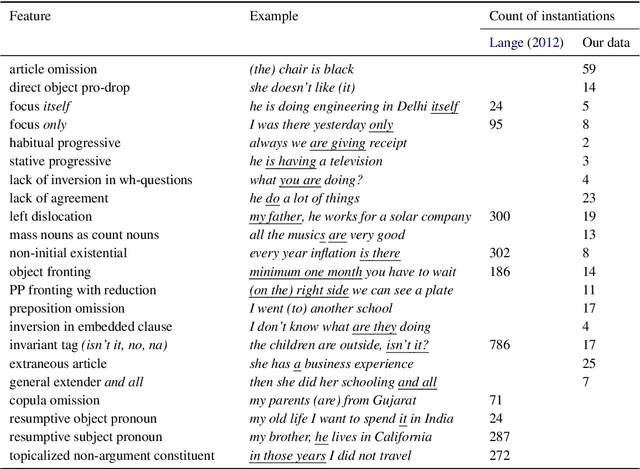
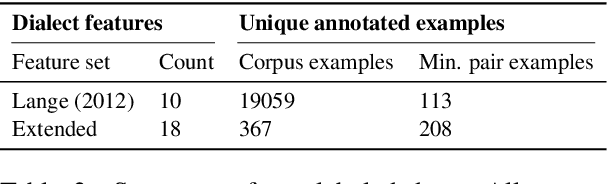
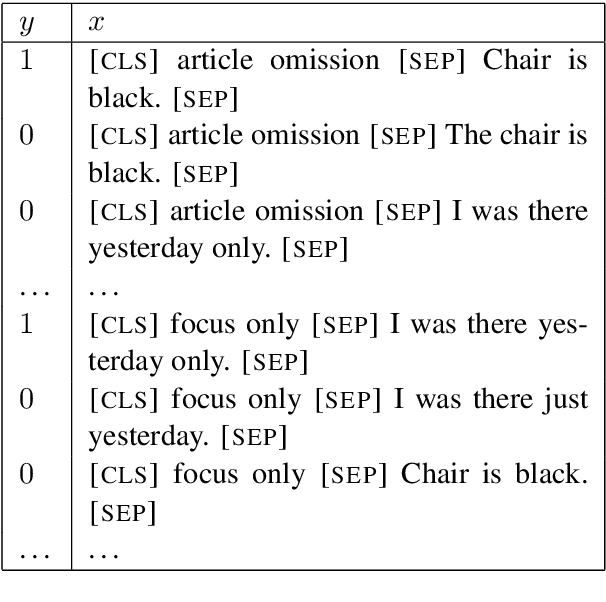
Linguists characterize dialects by the presence, absence, and frequency of dozens of interpretable features. Detecting these features in text has applications to social science and dialectology, and can be used to assess the robustness of natural language processing systems to dialect differences. For most dialects, large-scale annotated corpora for these features are unavailable, making it difficult to train recognizers. Linguists typically define dialect features by providing a small number of minimal pairs, which are paired examples distinguished only by whether the feature is present, while holding everything else constant. In this paper, we present two multitask learning architectures for recognizing dialect features, both based on pretrained transformers. We evaluate these models on two test sets of Indian English, annotated for a total of 22 dialect features. We find these models learn to recognize many features with high accuracy; crucially, a few minimal pairs can be nearly as effective for training as thousands of labeled examples. We also demonstrate the downstream applicability of our dialect feature detection model as a dialect density measure and as a dialect classifier.