 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reason in Large Theories without Imitation
Paper and Code
May 25, 2019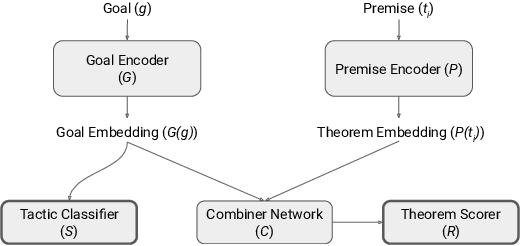

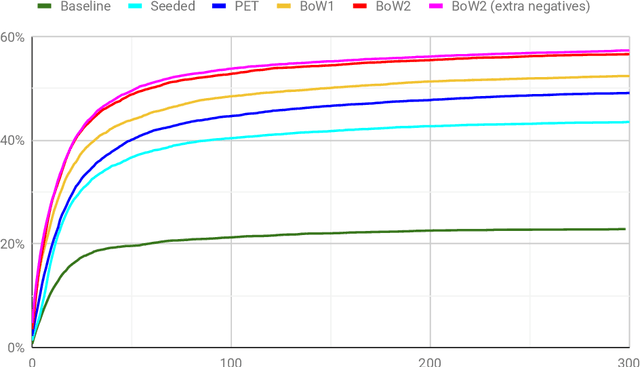

Automated theorem proving in large theories can be learned via reinforcement learning over an indefinitely growing action space. In order to select actions, one performs nearest neighbor lookups in the knowledge base to find premises to be applied. Here we address the exploration for reinforcement learning in this space. Approaches (like epsilon-greedy strategy) that sample actions uniformly do not scale to this scenario as most actions lead to dead ends and unsuccessful proofs which are not useful for training our models. In this paper, we compare approaches that select premises using randomly initialized similarity measures and mixing them with the proposals of the learned model. We evaluate these on the HOList benchmark for tactics based higher order theorem proving. We implement an automated theorem prover named DeepHOL-Zero that does not use any of the human proofs and show that our improved exploration method manages to expand the training set continuously. DeepHOL-Zero outperforms the best theorem prover trained by imitation learning alone.