 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Communicate Using Counterfactual Reasoning
Paper and Code

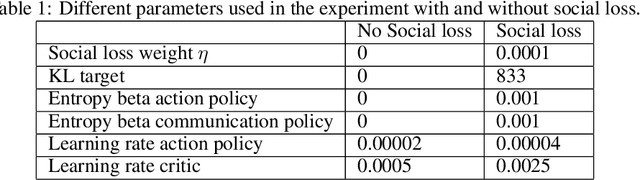
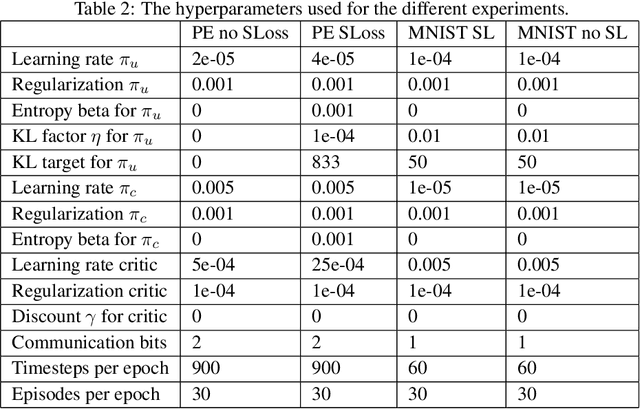
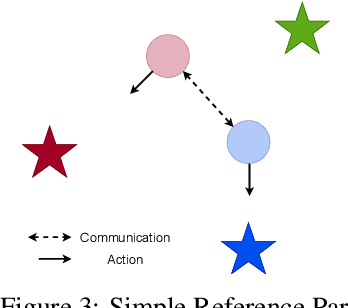
This paper introduces a new approach for multi-agent communication learning called multi-agent counterfactual communication (MACC) learning. Many real-world problems are currently tackled using multi-agent techniques. However, in many of these tasks the agents do not observe the full state of the environment but only a limited observation. This absence of knowledge about the full state makes completing the objectives significantly more complex or even impossible. The key to this problem lies in sharing observation information between agents or learning how to communicate the essential data. In this paper we present a novel multi-agent communication learning approach called MACC. It addresses the partial observability problem of the agents. MACC lets the agent learn the action policy and the communication policy simultaneously. We focus on decentralized Markov Decision Processes (Dec-MDP), where the agents have joint observability. This means that the full state of the environment can be determined using the observations of all agents. MACC uses counterfactual reasoning to train both the action and the communication policy. This allows the agents to anticipate on how other agents will react to certain messages and on how the environment will react to certain actions, allowing them to learn more effective policies. MACC uses actor-critic with a centralized critic and decentralized actors. The critic is used to calculate an advantage for both the action and communication policy. We demonstrate our method by applying it on the Simple Reference Particle environment of OpenAI and a MNIST game. Our results are compared with a communication and non-communication baseline. These experiments demonstrate that MACC is able to train agents for each of these problems with effective communication policies.