 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Act Greedily: Polymatroid Semi-Bandits
Paper and Code
Nov 21, 2014
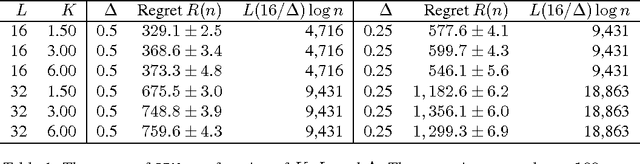
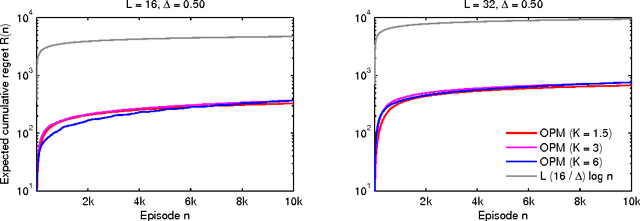
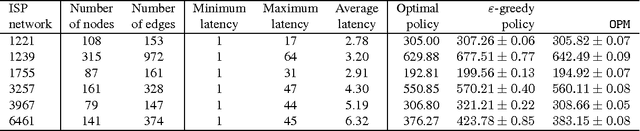
Many important optimization problems, such as the minimum spanning tree and minimum-cost flow, can be solved optimally by a greedy method. In this work, we study a learning variant of these problems, where the model of the problem is unknown and has to be learned by interacting repeatedly with the environment in the bandit setting. We formalize our learning problem quite generally, as learning how to maximize an unknown modular function on a known polymatroid. We propose a computationally efficient algorithm for solving our problem and bound its expected cumulative regret. Our gap-dependent upper bound is tight up to a constant and our gap-free upper bound is tight up to polylogarithmic factors. Finally, we evaluate our method on three problems and demonstrate that it is practical.