 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the Distribution: A Unified Distillation Paradigm for Fast Uncertainty Estimation in Computer Vision
Paper and Code
Jul 31, 2020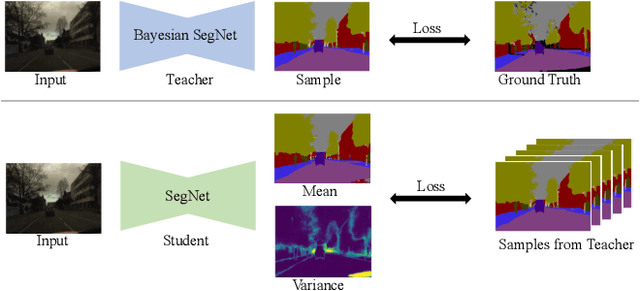
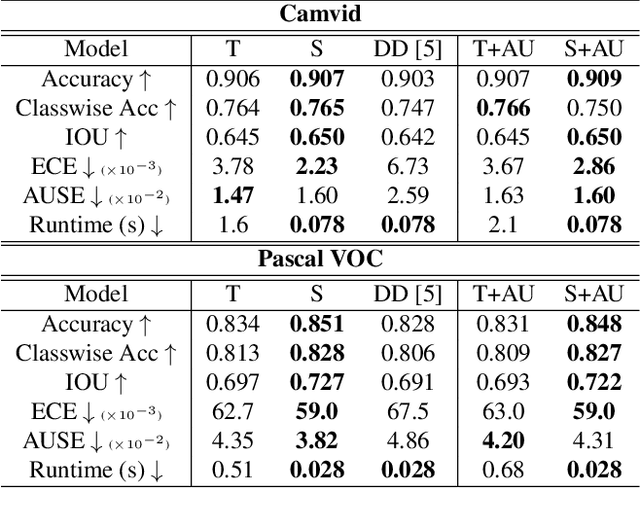

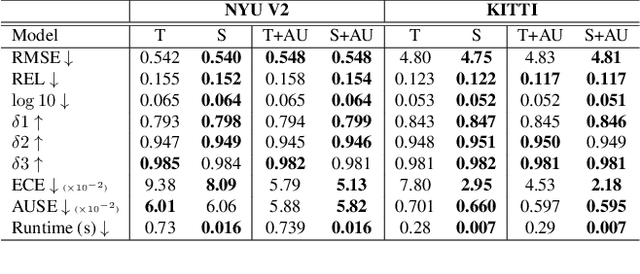
Calibrated estimates of uncertainty are critical for many real-world computer vision applications of deep learning. While there are several widely-used uncertainty estimation methods, dropout inference stands out for its simplicity and efficacy. This technique, however, requires multiple forward passes through the network during inference and therefore can be too resource-intensive to be deployed in real-time applications. To tackle this issue, we propose a unified distillation paradigm for learning the conditional predictive distribution of a pre-trained dropout model for fast uncertainty estimation of both aleatoric and epistemic uncertainty at the same time. We empirically test the effectiveness of the proposed method on both semantic segmentation and depth estimation tasks, and observe that the student model can well approximate the probability distribution generated by the teacher model, i.e the pre-trained dropout model. In addition to a significant boost in speed, we demonstrate the quality of uncertainty estimates and the overall predictive performance can also be improved with the proposed method.