Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning State Abstractions for Transfer in Continuous Control
Paper and Code
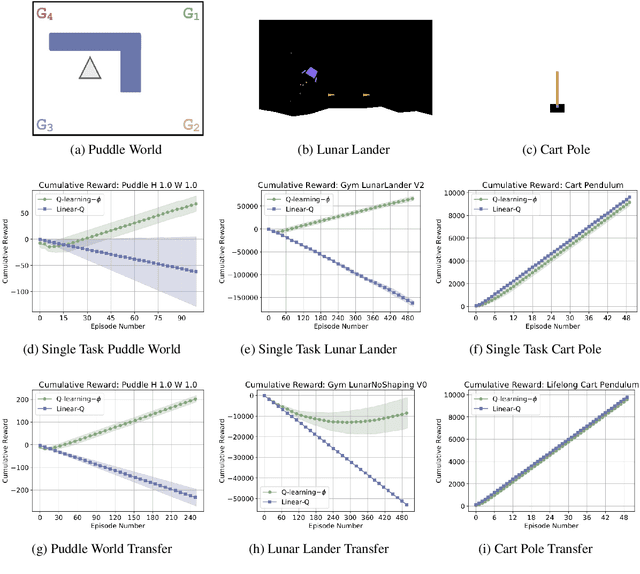
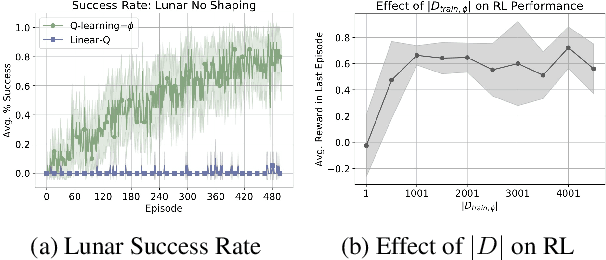
Can simple algorithms with a good representation solve challenging reinforcement learning problems? In this work, we answer this question in the affirmative, where we take "simple learning algorithm" to be tabular Q-Learning, the "good representations" to be a learned state abstraction, and "challenging problems" to be continuous control tasks. Our main contribution is a learning algorithm that abstracts a continuous state-space into a discrete one. We transfer this learned representation to unseen problems to enable effective learning. We provide theory showing that learned abstractions maintain a bounded value loss, and we report experiments showing that the abstractions empower tabular Q-Learning to learn efficiently in unseen tasks.
View paper on