 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Source Phrase Representations for Neural Machine Translation
Paper and Code
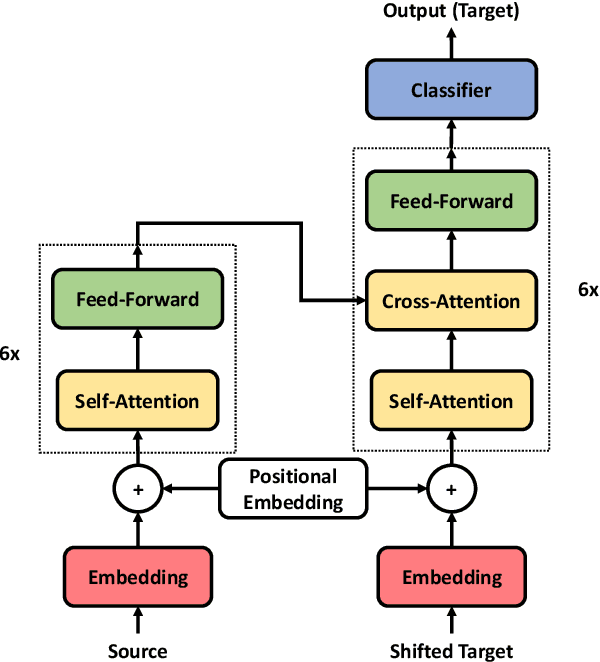
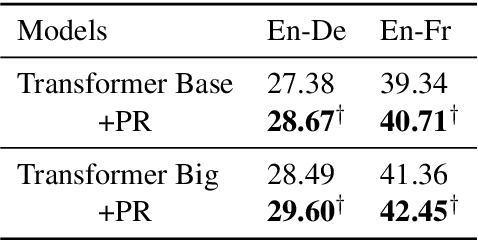
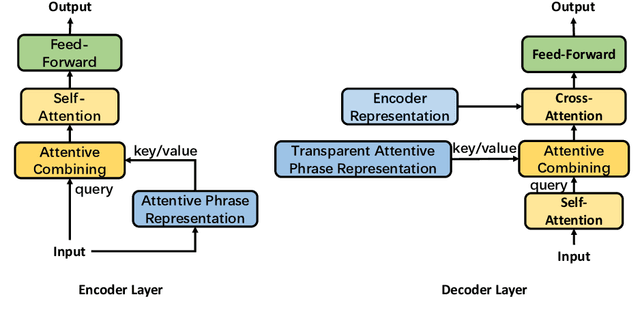
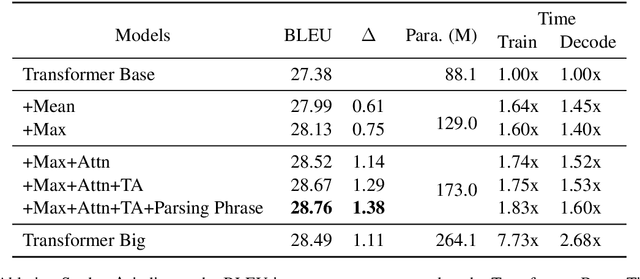
The Transformer translation model (Vaswani et al., 2017) based on a multi-head attention mechanism can be computed effectively in parallel and has significantly pushed forward the performance of Neural Machine Translation (NMT). Though intuitively the attentional network can connect distant words via shorter network paths than RNNs, empirical analysis demonstrates that it still has difficulty in fully capturing long-distance dependencies (Tang et al., 2018). Considering that modeling phrases instead of words has significantly improved the Statistical Machine Translation (SMT) approach through the use of larger translation blocks ("phrases") and its reordering ability, modeling NMT at phrase level is an intuitive proposal to help the model capture long-distance relationships. In this paper, we first propose an attentive phrase representation generation mechanism which is able to generate phrase representations from corresponding token representations. In addition, we incorporate the generated phrase representations into the Transformer translation model to enhance its ability to capture long-distance relationships. In our experiments, we obtain significant improvements on the WMT 14 English-German and English-French tasks on top of the strong Transformer baseline, which shows the effectiveness of our approach. Our approach helps Transformer Base models perform at the level of Transformer Big models, and even significantly better for long sentences, but with substantially fewer parameters and training steps. The fact that phrase representations help even in the big setting further supports our conjecture that they make a valuable contribution to long-distance relations.