 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Self-Imitating Diverse Policies
Paper and Code



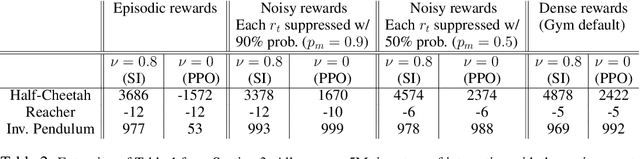
Deep reinforcement learning algorithms, including policy gradient methods and Q-learning, have been widely applied to a variety of decision-making problems. Their success has relied heavily on having very well designed dense reward signals, and therefore, they often perform badly on the sparse or episodic reward settings. Trajectory-based policy optimization methods, such as cross-entropy method and evolution strategies, do not take into consideration the temporal nature of the problem and often suffer from high sample complexity. Scaling up the efficiency of RL algorithms to real-world problems with sparse or episodic rewards is therefore a pressing need. In this work, we present a new perspective of policy optimization and introduce a self-imitation learning algorithm that exploits and explores well in the sparse and episodic reward settings. First, we view each policy as a state-action visitation distribution and formulate policy optimization as a divergence minimization problem. Then, we show that, with Jensen-Shannon divergence, this divergence minimization problem can be reduced into a policy-gradient algorithm with dense reward learned from experience replays. Experimental results indicate that our algorithm works comparable to existing algorithms in the dense reward setting, and significantly better in the sparse and episodic settings. To encourage exploration, we further apply the Stein variational policy gradient descent with the Jensen-Shannon kernel to learn multiple diverse policies and demonstrate its effectiveness on a number of challenging tasks.