 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Sample-Specific Models with Low-Rank Personalized Regression
Paper and Code

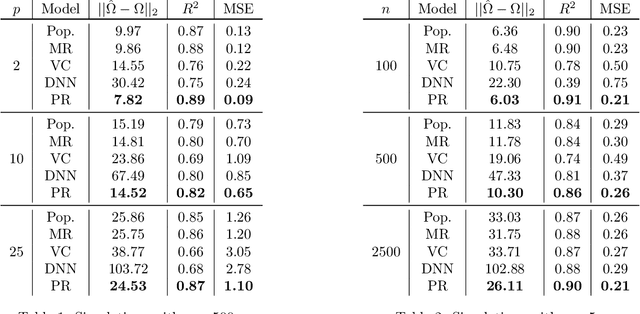
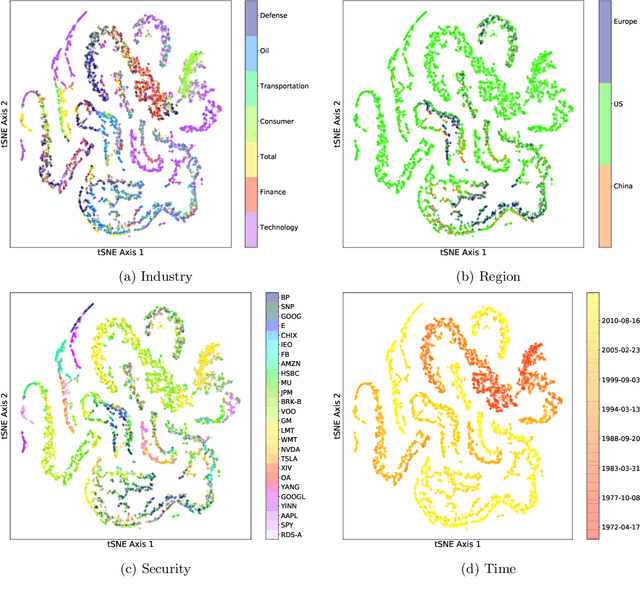
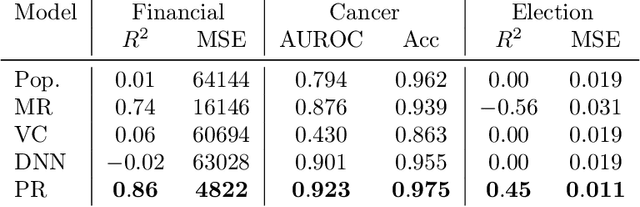
Modern applications of machine learning (ML) deal with increasingly heterogeneous datasets comprised of data collected from overlapping latent subpopulations. As a result, traditional models trained over large datasets may fail to recognize highly predictive localized effects in favour of weakly predictive global patterns. This is a problem because localized effects are critical to developing individualized policies and treatment plans in applications ranging from precision medicine to advertising. To address this challenge, we propose to estimate sample-specific models that tailor inference and prediction at the individual level. In contrast to classical ML models that estimate a single, complex model (or only a few complex models), our approach produces a model personalized to each sample. These sample-specific models can be studied to understand subgroup dynamics that go beyond coarse-grained class labels. Crucially, our approach does not assume that relationships between samples (e.g. a similarity network) are known a priori. Instead, we use unmodeled covariates to learn a latent distance metric over the samples. We apply this approach to financial, biomedical, and electoral data as well as simulated data and show that sample-specific models provide fine-grained interpretations of complicated phenomena without sacrificing predictive accuracy compared to state-of-the-art models such as deep neural networks.