 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Reinforced Attentional Representation for End-to-End Visual Tracking
Paper and Code
Aug 28, 2019
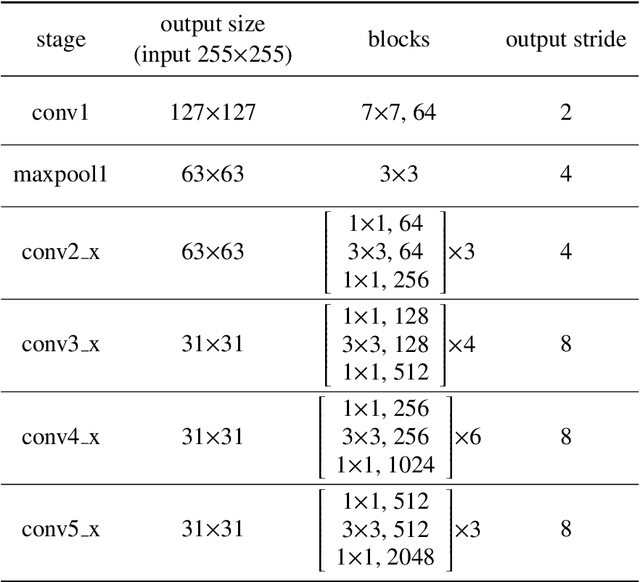
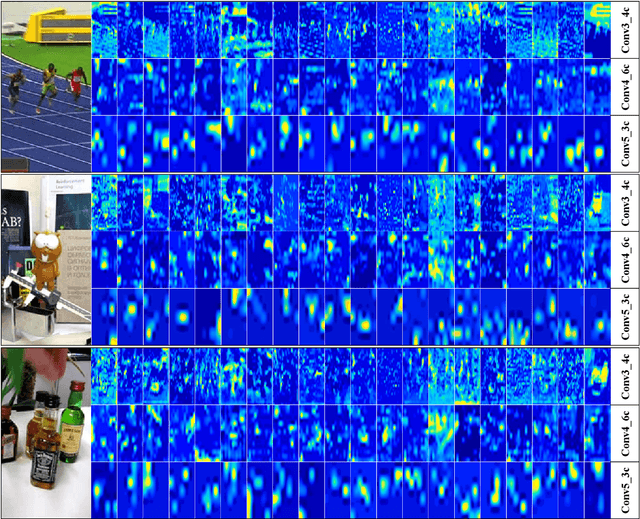
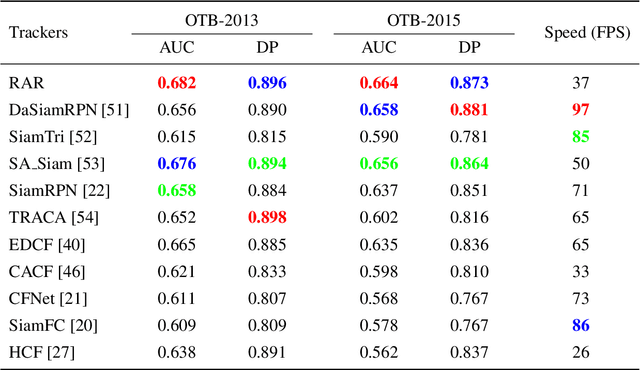
Despite the fact that tremendous advances have been made by numerous recent tracking approaches in the last decade, how to achieve high-performance visual tracking is still an open problem. In this paper, we propose an end-to-end network model to learn reinforced attentional representation for accurate target object discrimination and localization. We utilize a novel hierarchical attentional module with long short-term memory and multi-layer perceptrons to leverage both inter- and intra-frame attention to effectively facilitate visual pattern emphasis. Moreover, we incorporate a contextual attentional correlation filter into the backbone network to make our model be trained in an end-to-end fashion. Our proposed approach not only takes full advantage of informative geometries and semantics, but also updates correlation filters online without the backbone network fine-tuning to enable adaptation of target appearance variations. Extensive experiments conducted on several popular benchmark datasets demonstrate the effectiveness and efficiency of our proposed approach while remaining computational efficiency.