Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Policies with External Memory
Paper and Code
Mar 02, 2001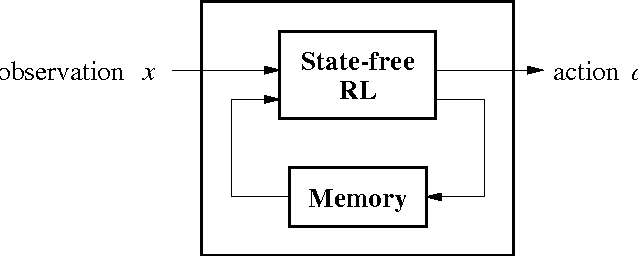

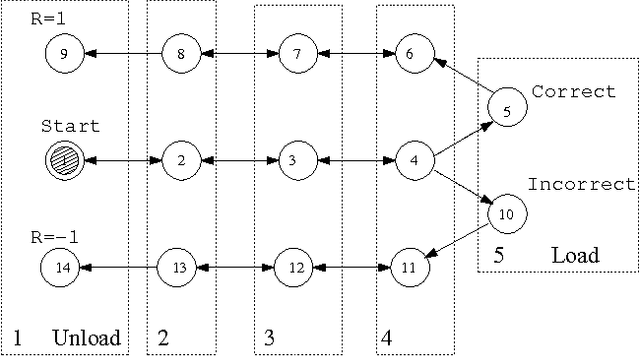
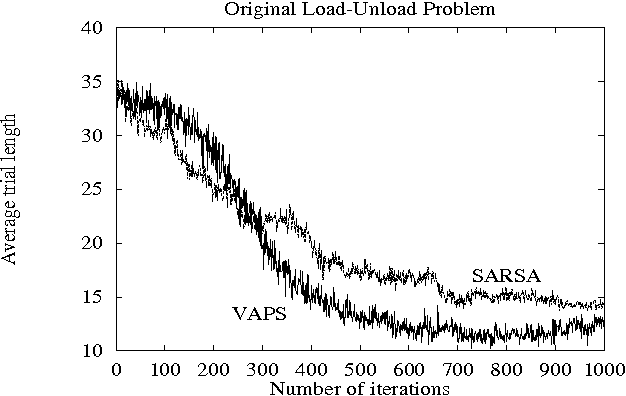
In order for an agent to perform well in partially observable domains, it is usually necessary for actions to depend on the history of observations. In this paper, we explore a {\it stigmergic} approach, in which the agent's actions include the ability to set and clear bits in an external memory, and the external memory is included as part of the input to the agent. In this case, we need to learn a reactive policy in a highly non-Markovian domain. We explore two algorithms: SARSA(\lambda), which has had empirical success in partially observable domains, and VAPS, a new algorithm due to Baird and Moore, with convergence guarantees in partially observable domains. We compare the performance of these two algorithms on benchmark problems.
* In Bratko, I., and Dzeroski, S., eds., Machine Learning:
Proceedings of the Sixteenth International Conference, pp. 307-314. Morgan
Kaufmann, San Francisco, CA * 8 pages
View paper on