 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Policies for Continuous Control via Transition Models
Paper and Code
Sep 16, 2022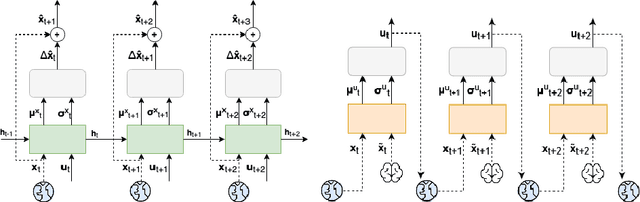
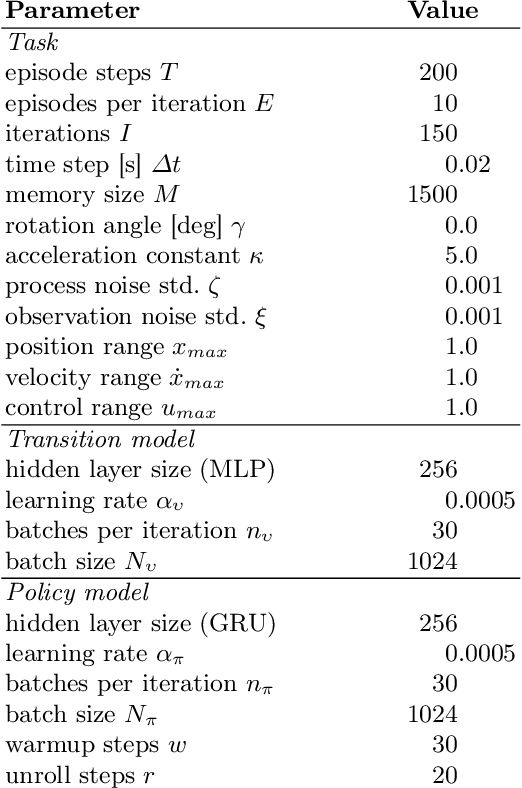
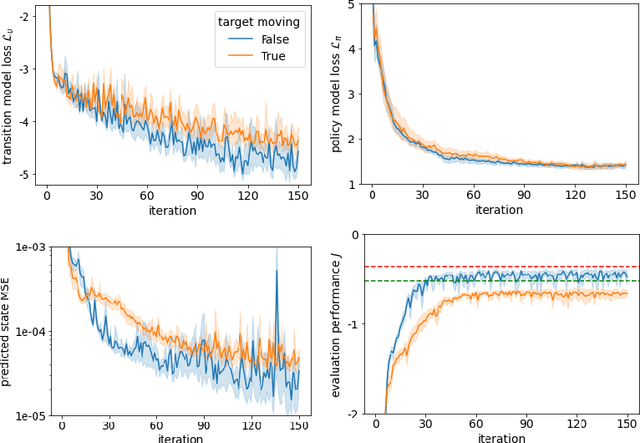
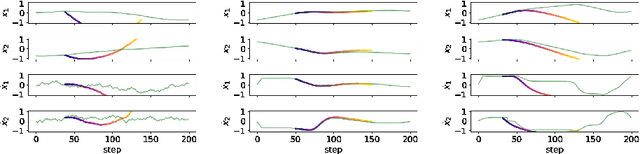
It is doubtful that animals have perfect inverse models of their limbs (e.g., what muscle contraction must be applied to every joint to reach a particular location in space). However, in robot control, moving an arm's end-effector to a target position or along a target trajectory requires accurate forward and inverse models. Here we show that by learning the transition (forward) model from interaction, we can use it to drive the learning of an amortized policy. Hence, we revisit policy optimization in relation to the deep active inference framework and describe a modular neural network architecture that simultaneously learns the system dynamics from prediction errors and the stochastic policy that generates suitable continuous control commands to reach a desired reference position. We evaluated the model by comparing it against the baseline of a linear quadratic regulator, and conclude with additional steps to take toward human-like motor control.