 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Mutual Modulation for Self-Supervised Cross-Modal Super-Resolution
Paper and Code

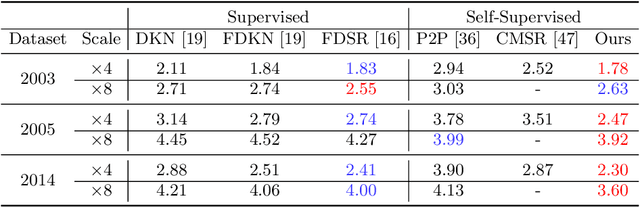
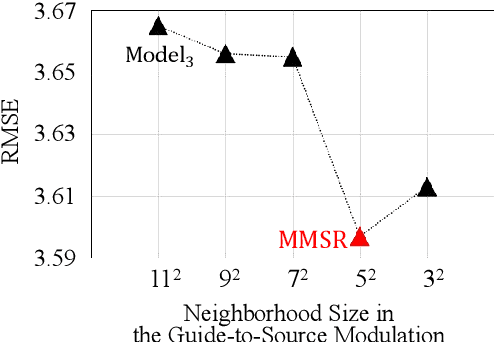
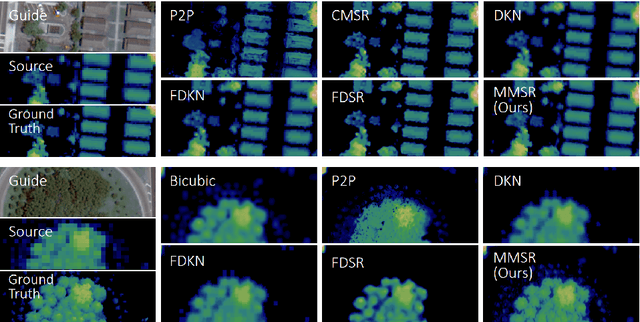
Self-supervised cross-modal super-resolution (SR) can overcome the difficulty of acquiring paired training data, but is challenging because only low-resolution (LR) source and high-resolution (HR) guide images from different modalities are available. Existing methods utilize pseudo or weak supervision in LR space and thus deliver results that are blurry or not faithful to the source modality. To address this issue, we present a mutual modulation SR (MMSR) model, which tackles the task by a mutual modulation strategy, including a source-to-guide modulation and a guide-to-source modulation. In these modulations, we develop cross-domain adaptive filters to fully exploit cross-modal spatial dependency and help induce the source to emulate the resolution of the guide and induce the guide to mimic the modality characteristics of the source. Moreover, we adopt a cycle consistency constraint to train MMSR in a fully self-supervised manner. Experiments on various tasks demonstrate the state-of-the-art performance of our MMSR.