 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Monocular Visual Odometry via Self-Supervised Long-Term Modeling
Paper and Code

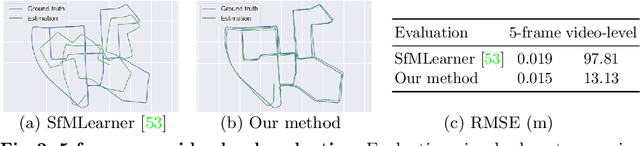
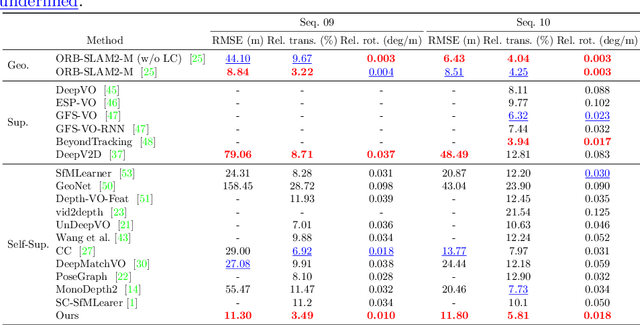
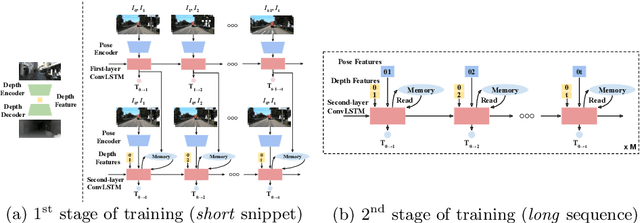
Monocular visual odometry (VO) suffers severely from error accumulation during frame-to-frame pose estimation. In this paper, we present a self-supervised learning method for VO with special consideration for consistency over longer sequences. To this end, we model the long-term dependency in pose prediction using a pose network that features a two-layer convolutional LSTM module. We train the networks with purely self-supervised losses, including a cycle consistency loss that mimics the loop closure module in geometric VO. Inspired by prior geometric systems, we allow the networks to see beyond a small temporal window during training, through a novel a loss that incorporates temporally distant (e.g., O(100)) frames. Given GPU memory constraints, we propose a stage-wise training mechanism, where the first stage operates in a local time window and the second stage refines the poses with a "global" loss given the first stage features. We demonstrate competitive results on several standard VO datasets, including KITTI and TUM RGB-D.