 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Hierarchical Priors in VAEs
Paper and Code
May 23, 2019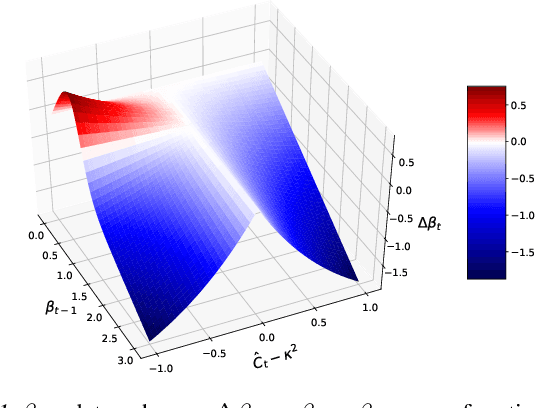

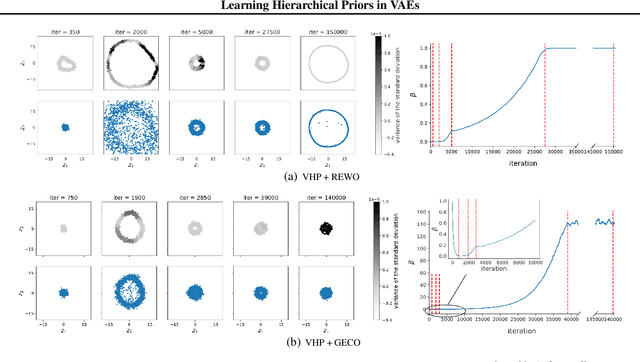
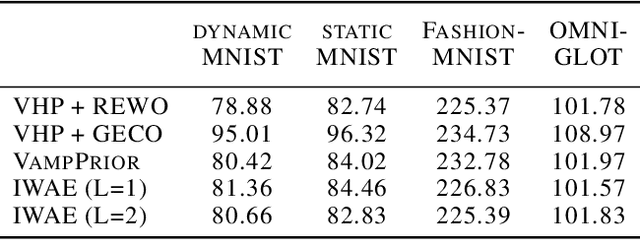
We propose to learn a hierarchical prior in the context of variational autoencoders to avoid the over-regularisation resulting from a standard normal prior distribution. To incentivise an informative latent representation of the data by learning a rich hierarchical prior, we formulate the objective function as the Lagrangian of a constrained-optimisation problem and propose an optimisation algorithm inspired by Taming VAEs. We introduce a graph-based interpolation method, which shows that the topology of the learned latent representation corresponds to the topology of the data manifold---and present several examples, where desired properties of latent representation such as smoothness and simple explanatory factors are learned by the prior. Furthermore, we validate our approach on standard datasets, obtaining state-of-the-art test log-likelihoods.