 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Imperfect Human Feedback: a Tale from Corruption-Robust Dueling
Paper and Code
May 18, 2024

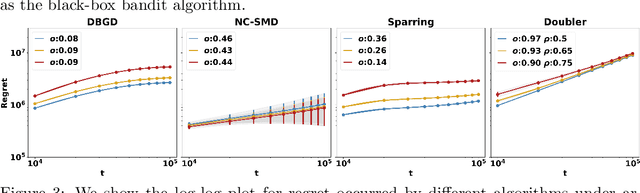

This paper studies Learning from Imperfect Human Feedback (LIHF), motivated by humans' potential irrationality or imperfect perception of true preference. We revisit the classic dueling bandit problem as a model of learning from comparative human feedback, and enrich it by casting the imperfection in human feedback as agnostic corruption to user utilities. We start by identifying the fundamental limits of LIHF and prove a regret lower bound of $\Omega(\max\{T^{1/2},C\})$, even when the total corruption $C$ is known and when the corruption decays gracefully over time (i.e., user feedback becomes increasingly more accurate). We then turn to design robust algorithms applicable in real-world scenarios with arbitrary corruption and unknown $C$. Our key finding is that gradient-based algorithms enjoy a smooth efficiency-robustness tradeoff under corruption by varying their learning rates. Specifically, under general concave user utility, Dueling Bandit Gradient Descent (DBGD) of Yue and Joachims (2009) can be tuned to achieve regret $O(T^{1-\alpha} + T^{ \alpha} C)$ for any given parameter $\alpha \in (0, \frac{1}{4}]$. Additionally, this result enables us to pin down the regret lower bound of the standard DBGD (the $\alpha=1/4$ case) as $\Omega(T^{3/4})$ for the first time, to the best of our knowledge. For strongly concave user utility we show a better tradeoff: there is an algorithm that achieves $O(T^{\alpha} + T^{\frac{1}{2}(1-\alpha)}C)$ for any given $\alpha \in [\frac{1}{2},1)$. Our theoretical insights are corroborated by extensive experiments on real-world recommendation data.