 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Data-Rich Problems: A Case Study on Genetic Variant Calling
Paper and Code


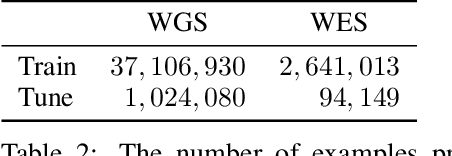
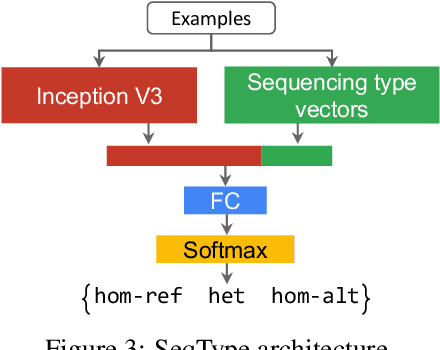
Next Generation Sequencing can sample the whole genome (WGS) or the 1-2% of the genome that codes for proteins called the whole exome (WES). Machine learning approaches to variant calling achieve high accuracy in WGS data, but the reduced number of training examples causes training with WES data alone to achieve lower accuracy. We propose and compare three different data augmentation strategies for improving performance on WES data: 1) joint training with WES and WGS data, 2) warmstarting the WES model from a WGS model, and 3) joint training with the sequencing type specified. All three approaches show improved accuracy over a model trained using just WES data, suggesting the ability of models to generalize insights from the greater WGS data while retaining performance on the specialized WES problem. These data augmentation approaches may apply to other problem areas in genomics, where several specialized models would each see only a subset of the genome.