 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from an Exploring Demonstrator: Optimal Reward Estimation for Bandits
Paper and Code
Jun 28, 2021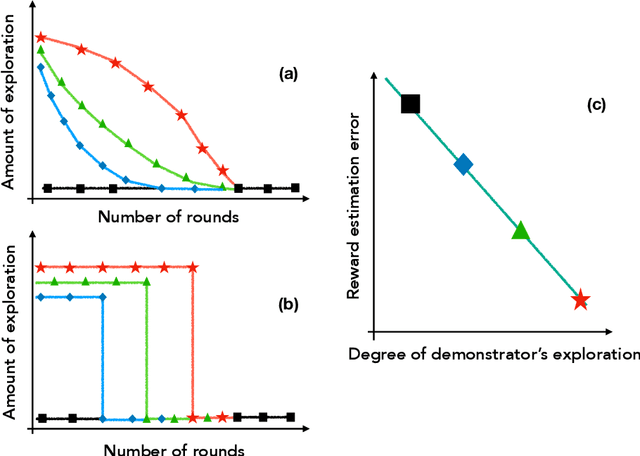
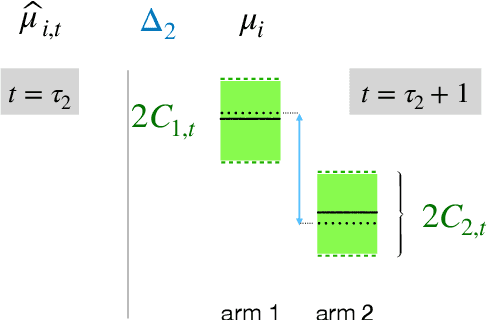
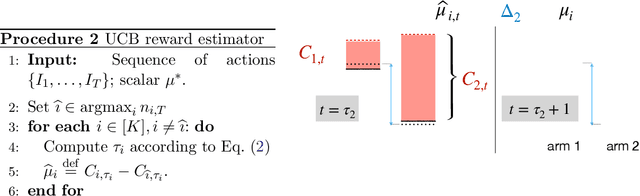
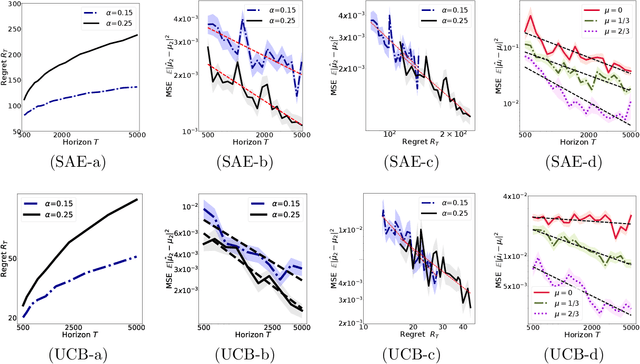
We introduce the "inverse bandit" problem of estimating the rewards of a multi-armed bandit instance from observing the learning process of a low-regret demonstrator. Existing approaches to the related problem of inverse reinforcement learning assume the execution of an optimal policy, and thereby suffer from an identifiability issue. In contrast, our paradigm leverages the demonstrator's behavior en route to optimality, and in particular, the exploration phase, to obtain consistent reward estimates. We develop simple and efficient reward estimation procedures for demonstrations within a class of upper-confidence-based algorithms, showing that reward estimation gets progressively easier as the regret of the algorithm increases. We match these upper bounds with information-theoretic lower bounds that apply to any demonstrator algorithm, thereby characterizing the optimal tradeoff between exploration and reward estimation. Extensive empirical evaluations on both synthetic data and simulated experimental design data from the natural sciences corroborate our theoretical results.