 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning and approximation capability of orthogonal super greedy algorithm
Paper and Code
Sep 18, 2014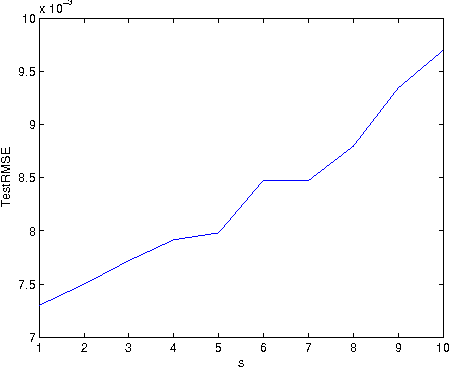
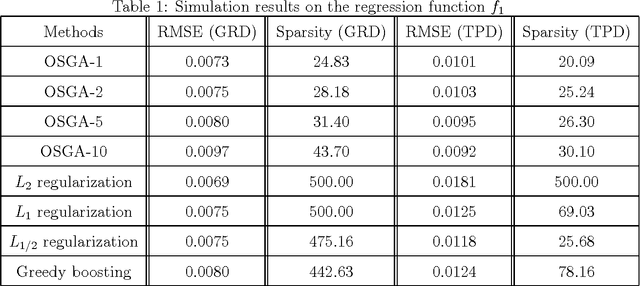


We consider the approximation capability of orthogonal super greedy algorithms (OSGA) and its applications in supervised learning. OSGA is concerned with selecting more than one atoms in each iteration step, which, of course, greatly reduces the computational burden when compared with the conventional orthogonal greedy algorithm (OGA). We prove that even for function classes that are not the convex hull of the dictionary, OSGA does not degrade the approximation capability of OGA provided the dictionary is incoherent. Based on this, we deduce a tight generalization error bound for OSGA learning. Our results show that in the realm of supervised learning, OSGA provides a possibility to further reduce the computational burden of OGA in the premise of maintaining its prominent generalization capability.