 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning an Animatable Detailed 3D Face Model from In-The-Wild Images
Paper and Code
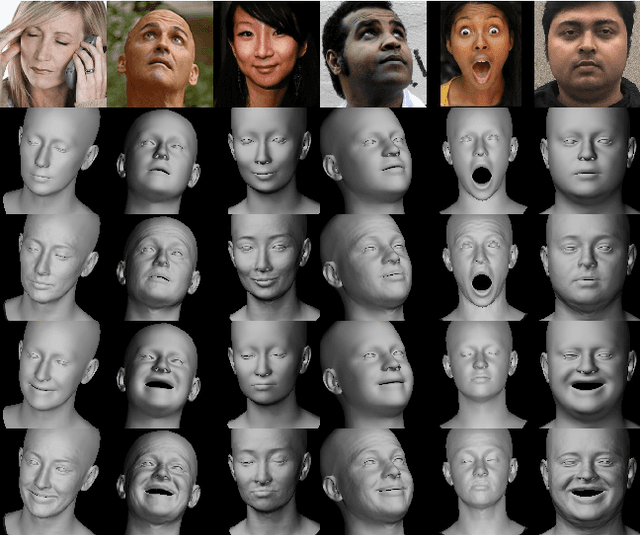
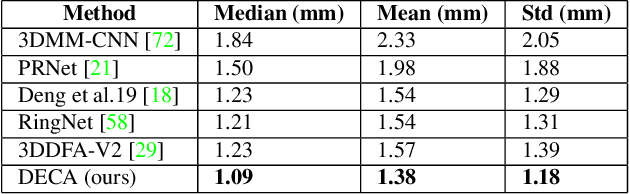
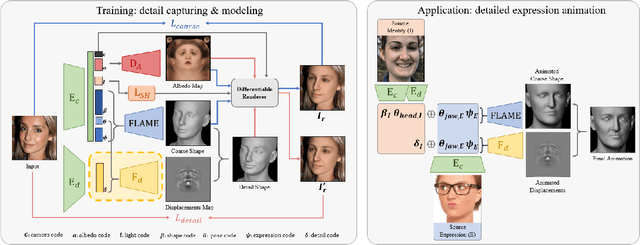
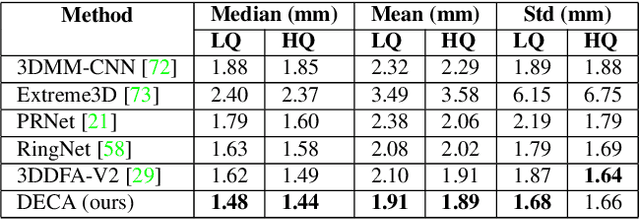
While current monocular 3D face reconstruction methods can recover fine geometric details, they suffer several limitations. Some methods produce faces that cannot be realistically animated because they do not model how wrinkles vary with expression. Other methods are trained on high-quality face scans and do not generalize well to in-the-wild images. We present the first approach to jointly learn a model with animatable detail and a detailed 3D face regressor from in-the-wild images that recovers shape details as well as their relationship to facial expressions. Our DECA (Detailed Expression Capture and Animation) model is trained to robustly produce a UV displacement map from a low-dimensional latent representation that consists of person-specific detail parameters and generic expression parameters, while a regressor is trained to predict detail, shape, albedo, expression, pose and illumination parameters from a single image. We introduce a novel detail-consistency loss to disentangle person-specific details and expression-dependent wrinkles. This disentanglement allows us to synthesize realistic person-specific wrinkles by controlling expression parameters while keeping person-specific details unchanged. DECA achieves state-of-the-art shape reconstruction accuracy on two benchmarks. Qualitative results on in-the-wild data demonstrate DECA's robustness and its ability to disentangle identity and expression dependent details enabling animation of reconstructed faces. The model and code are publicly available at https://github.com/YadiraF/DECA.