 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Structured Neural Network Policy for a Hopping Task
Paper and Code
Aug 06, 2018

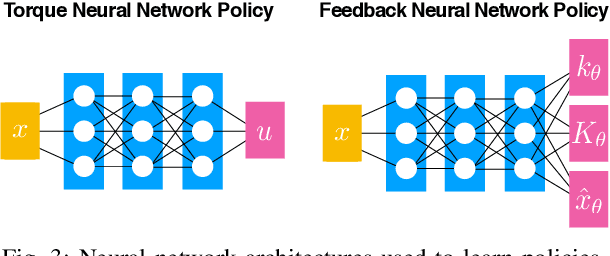
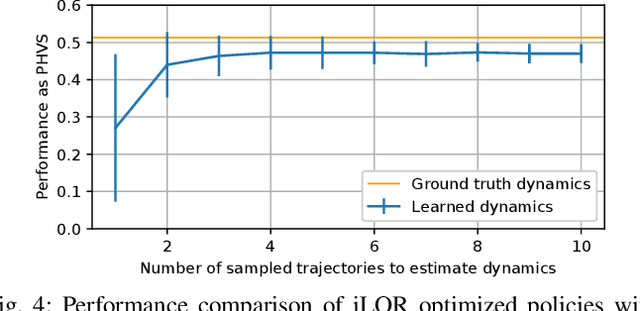
In this work we present a method for learning a reactive policy for a simple dynamic locomotion task involving hard impact and switching contacts where we assume the contact location and contact timing to be unknown. To learn such a policy, we use optimal control to optimize a local controller for a fixed environment and contacts. We learn the contact-rich dynamics for our underactuated systems along these trajectories in a sample efficient manner. We use the optimized policies to learn the reactive policy in form of a neural network. Using a new neural network architecture, we are able to preserve more information from the local policy and make its output interpretable in the sense that its output in terms of desired trajectories, feedforward commands and gains can be interpreted. Extensive simulations demonstrate the robustness of the approach to changing environments, outperforming a model-free gradient policy based methods on the same tasks in simulation. Finally, we show that the learned policy can be robustly transferred on a real robot.