 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Diffusion Model Policy from Rewards via Q-Score Matching
Paper and Code
Dec 18, 2023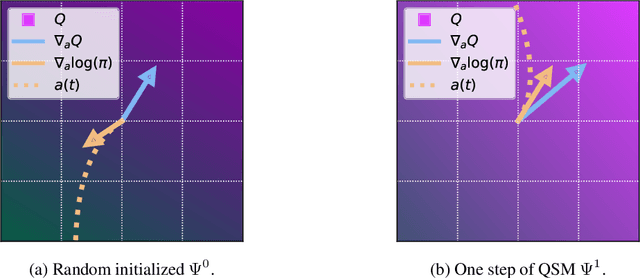
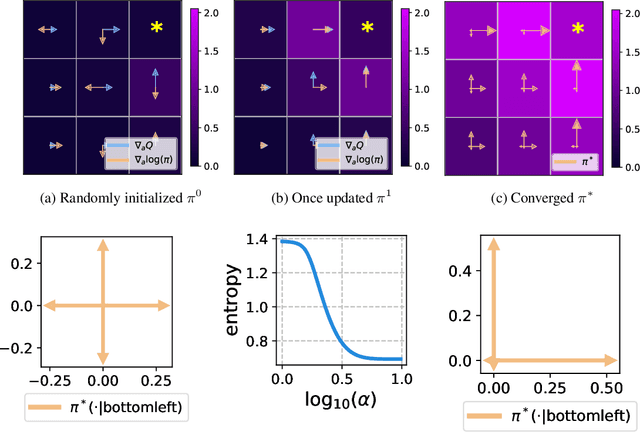
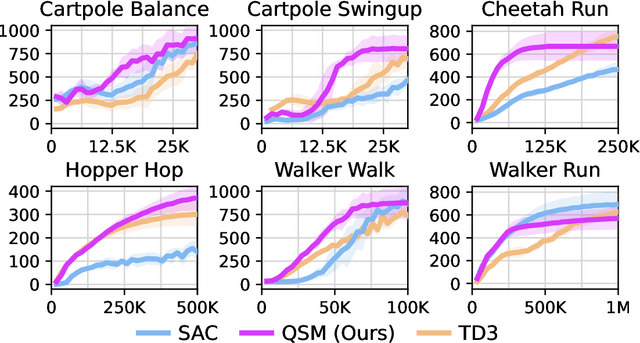
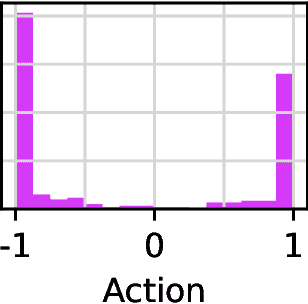
Diffusion models have become a popular choice for representing actor policies in behavior cloning and offline reinforcement learning. This is due to their natural ability to optimize an expressive class of distributions over a continuous space. However, previous works fail to exploit the score-based structure of diffusion models, and instead utilize a simple behavior cloning term to train the actor, limiting their ability in the actor-critic setting. In this paper, we focus on off-policy reinforcement learning and propose a new method for learning a diffusion model policy that exploits the linked structure between the score of the policy and the action gradient of the Q-function. We denote this method Q-score matching and provide theoretical justification for this approach. We conduct experiments in simulated environments to demonstrate the effectiveness of our proposed method and compare to popular baselines.