 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning 3D Deformation of Animals from 2D Images
Paper and Code
May 24, 2016
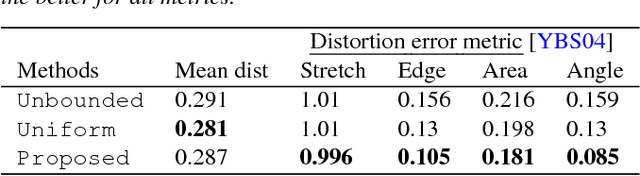
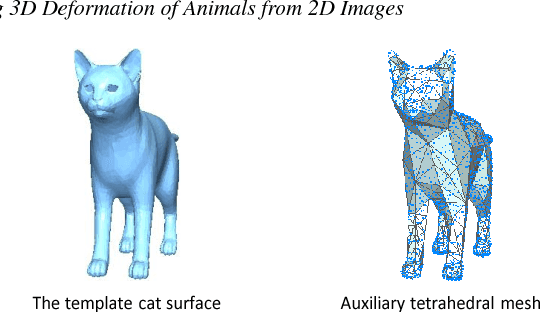

Understanding how an animal can deform and articulate is essential for a realistic modification of its 3D model. In this paper, we show that such information can be learned from user-clicked 2D images and a template 3D model of the target animal. We present a volumetric deformation framework that produces a set of new 3D models by deforming a template 3D model according to a set of user-clicked images. Our framework is based on a novel locally-bounded deformation energy, where every local region has its own stiffness value that bounds how much distortion is allowed at that location. We jointly learn the local stiffness bounds as we deform the template 3D mesh to match each user-clicked image. We show that this seemingly complex task can be solved as a sequence of convex optimization problems. We demonstrate the effectiveness of our approach on cats and horses, which are highly deformable and articulated animals. Our framework produces new 3D models of animals that are significantly more plausible than methods without learned stiffness.