 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn Zero-Constraint-Violation Policy in Model-Free Constrained Reinforcement Learning
Paper and Code
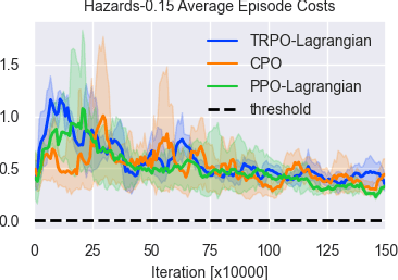

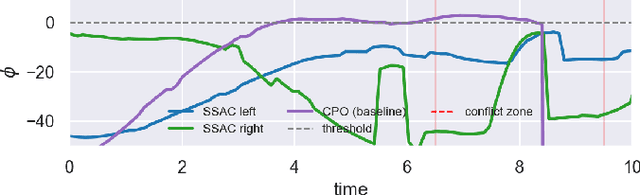
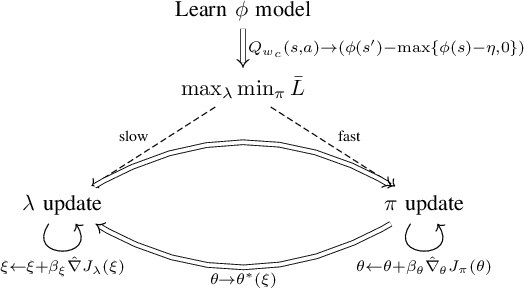
In the trial-and-error mechanism of reinforcement learning (RL), a notorious contradiction arises when we expect to learn a safe policy: how to learn a safe policy without enough data and prior model about the dangerous region? Existing methods mostly use the posterior penalty for dangerous actions, which means that the agent is not penalized until experiencing danger. This fact causes that the agent cannot learn a zero-violation policy even after convergence. Otherwise, it would not receive any penalty and lose the knowledge about danger. In this paper, we propose the safe set actor-critic (SSAC) algorithm, which confines the policy update using safety-oriented energy functions, or the safety indexes. The safety index is designed to increase rapidly for potentially dangerous actions, which allows us to locate the safe set on the action space, or the control safe set. Therefore, we can identify the dangerous actions prior to taking them, and further obtain a zero constraint-violation policy after convergence.We claim that we can learn the energy function in a model-free manner similar to learning a value function. By using the energy function transition as the constraint objective, we formulate a constrained RL problem. We prove that our Lagrangian-based solutions make sure that the learned policy will converge to the constrained optimum under some assumptions. The proposed algorithm is evaluated on both the complex simulation environments and a hardware-in-loop (HIL) experiment with a real controller from the autonomous vehicle. Experimental results suggest that the converged policy in all environments achieves zero constraint violation and comparable performance with model-based baselines.