 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn to Tour: Operator Design For Solution Feasibility Mapping in Pickup-and-delivery Traveling Salesman Problem
Paper and Code
Apr 17, 2024

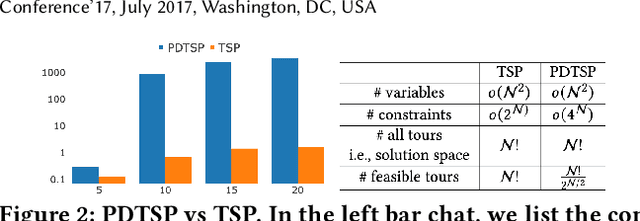
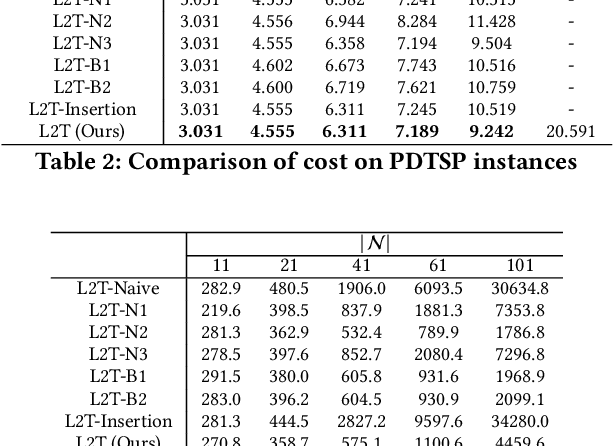
This paper aims to develop a learning method for a special class of traveling salesman problems (TSP), namely, the pickup-and-delivery TSP (PDTSP), which finds the shortest tour along a sequence of one-to-one pickup-and-delivery nodes. One-to-one here means that the transported people or goods are associated with designated pairs of pickup and delivery nodes, in contrast to that indistinguishable goods can be delivered to any nodes. In PDTSP, precedence constraints need to be satisfied that each pickup node must be visited before its corresponding delivery node. Classic operations research (OR) algorithms for PDTSP are difficult to scale to large-sized problems. Recently, reinforcement learning (RL) has been applied to TSPs. The basic idea is to explore and evaluate visiting sequences in a solution space. However, this approach could be less computationally efficient, as it has to potentially evaluate many infeasible solutions of which precedence constraints are violated. To restrict solution search within a feasible space, we utilize operators that always map one feasible solution to another, without spending time exploring the infeasible solution space. Such operators are evaluated and selected as policies to solve PDTSPs in an RL framework. We make a comparison of our method and baselines, including classic OR algorithms and existing learning methods. Results show that our approach can find tours shorter than baselines.