 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLazier Than Lazy Greedy
Paper and Code
Nov 28, 2014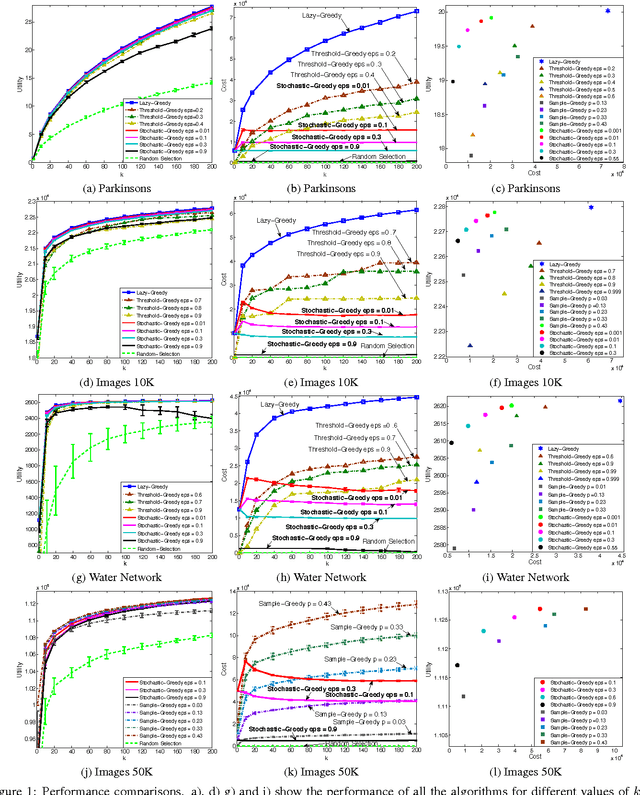
Is it possible to maximize a monotone submodular function faster than the widely used lazy greedy algorithm (also known as accelerated greedy), both in theory and practice? In this paper, we develop the first linear-time algorithm for maximizing a general monotone submodular function subject to a cardinality constraint. We show that our randomized algorithm, STOCHASTIC-GREEDY, can achieve a $(1-1/e-\varepsilon)$ approximation guarantee, in expectation, to the optimum solution in time linear in the size of the data and independent of the cardinality constraint. We empirically demonstrate the effectiveness of our algorithm on submodular functions arising in data summarization, including training large-scale kernel methods, exemplar-based clustering, and sensor placement. We observe that STOCHASTIC-GREEDY practically achieves the same utility value as lazy greedy but runs much faster. More surprisingly, we observe that in many practical scenarios STOCHASTIC-GREEDY does not evaluate the whole fraction of data points even once and still achieves indistinguishable results compared to lazy greedy.