 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayout-Bridging Text-to-Image Synthesis
Paper and Code
Aug 12, 2022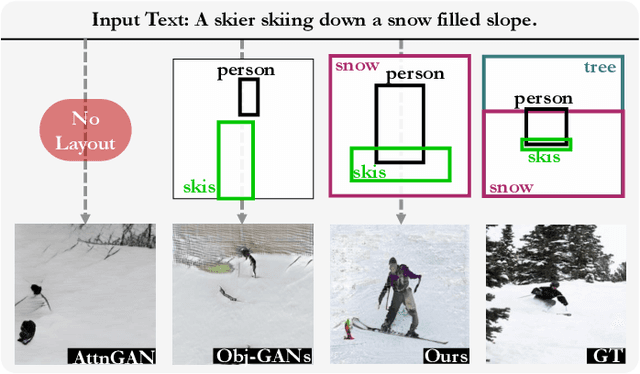

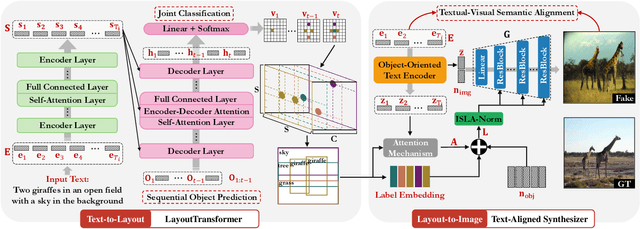
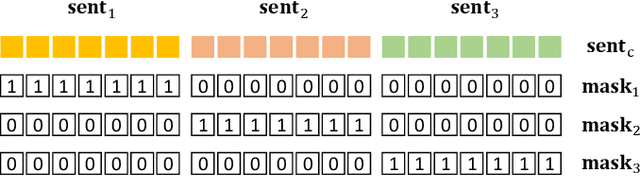
The crux of text-to-image synthesis stems from the difficulty of preserving the cross-modality semantic consistency between the input text and the synthesized image. Typical methods, which seek to model the text-to-image mapping directly, could only capture keywords in the text that indicates common objects or actions but fail to learn their spatial distribution patterns. An effective way to circumvent this limitation is to generate an image layout as guidance, which is attempted by a few methods. Nevertheless, these methods fail to generate practically effective layouts due to the diversity of input text and object location. In this paper we push for effective modeling in both text-to-layout generation and layout-to-image synthesis. Specifically, we formulate the text-to-layout generation as a sequence-to-sequence modeling task, and build our model upon Transformer to learn the spatial relationships between objects by modeling the sequential dependencies between them. In the stage of layout-to-image synthesis, we focus on learning the textual-visual semantic alignment per object in the layout to precisely incorporate the input text into the layout-to-image synthesizing process. To evaluate the quality of generated layout, we design a new metric specifically, dubbed Layout Quality Score, which considers both the absolute distribution errors of bounding boxes in the layout and the mutual spatial relationships between them. Extensive experiments on three datasets demonstrate the superior performance of our method over state-of-the-art methods on both predicting the layout and synthesizing the image from the given text.