 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Stepsize Gradient Descent for Logistic Loss: Non-Monotonicity of the Loss Improves Optimization Efficiency
Paper and Code
Feb 24, 2024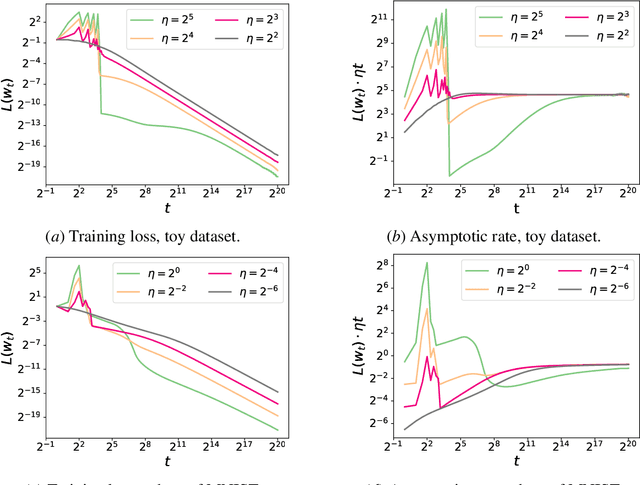

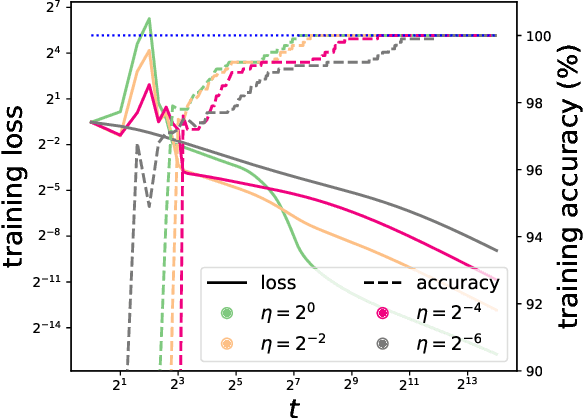
We consider gradient descent (GD) with a constant stepsize applied to logistic regression with linearly separable data, where the constant stepsize $\eta$ is so large that the loss initially oscillates. We show that GD exits this initial oscillatory phase rapidly -- in $\mathcal{O}(\eta)$ steps -- and subsequently achieves an $\tilde{\mathcal{O}}(1 / (\eta t) )$ convergence rate after $t$ additional steps. Our results imply that, given a budget of $T$ steps, GD can achieve an accelerated loss of $\tilde{\mathcal{O}}(1/T^2)$ with an aggressive stepsize $\eta:= \Theta( T)$, without any use of momentum or variable stepsize schedulers. Our proof technique is versatile and also handles general classification loss functions (where exponential tails are needed for the $\tilde{\mathcal{O}}(1/T^2)$ acceleration), nonlinear predictors in the neural tangent kernel regime, and online stochastic gradient descent (SGD) with a large stepsize, under suitable separability conditions.