Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLandscape of Sparse Linear Network: A Brief Investigation
Paper and Code
Sep 16, 2020

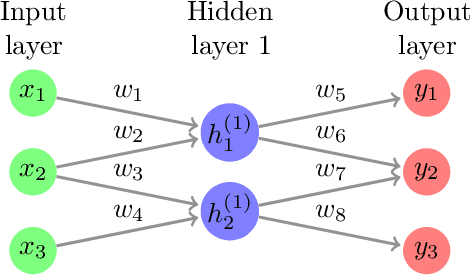

Network pruning, or sparse network has a long history and practical significance in modern application. A major concern for neural network training is that the non-convexity of the associated loss functions may cause bad landscape. We focus on analyzing sparse linear network generated from weight pruning strategy. With no unrealistic assumption, we prove the following statements for the squared loss objective of sparse linear neural networks: 1) every local minimum is a global minimum for scalar output with any sparse structure, or non-intersect sparse first layer and dense other layers with whitened data; 2) sparse linear networks have sub-optimal local-min for only sparse first layer or three target dimensions.
View paper on