 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAE: Language-Aware Encoder for Monolingual and Multilingual ASR
Paper and Code

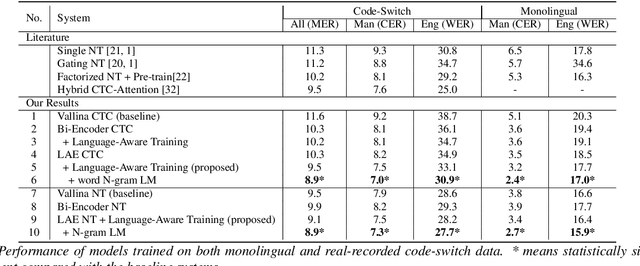
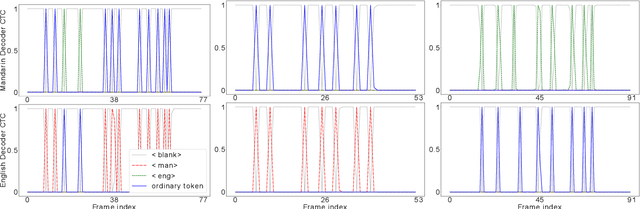

Despite the rapid progress in automatic speech recognition (ASR) research, recognizing multilingual speech using a unified ASR system remains highly challenging. Previous works on multilingual speech recognition mainly focus on two directions: recognizing multiple monolingual speech or recognizing code-switched speech that uses different languages interchangeably within a single utterance. However, a pragmatic multilingual recognizer is expected to be compatible with both directions. In this work, a novel language-aware encoder (LAE) architecture is proposed to handle both situations by disentangling language-specific information and generating frame-level language-aware representations during encoding. In the LAE, the primary encoding is implemented by the shared block while the language-specific blocks are used to extract specific representations for each language. To learn language-specific information discriminatively, a language-aware training method is proposed to optimize the language-specific blocks in LAE. Experiments conducted on Mandarin-English code-switched speech suggest that the proposed LAE is capable of discriminating different languages in frame-level and shows superior performance on both monolingual and multilingual ASR tasks. With either a real-recorded or simulated code-switched dataset, the proposed LAE achieves statistically significant improvements on both CTC and neural transducer systems. Code is released