 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabeled Data Selection for Category Discovery
Paper and Code
Jun 07, 2024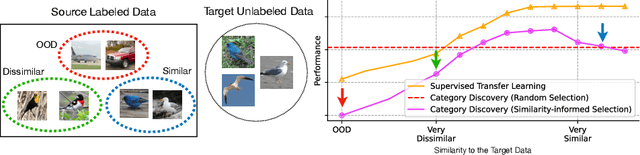
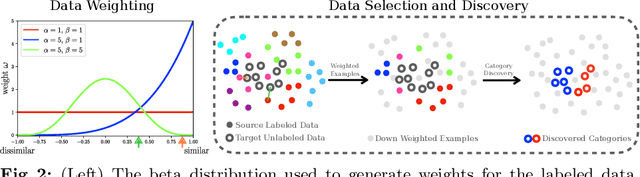


Category discovery methods aim to find novel categories in unlabeled visual data. At training time, a set of labeled and unlabeled images are provided, where the labels correspond to the categories present in the images. The labeled data provides guidance during training by indicating what types of visual properties and features are relevant for performing discovery in the unlabeled data. As a result, changing the categories present in the labeled set can have a large impact on what is ultimately discovered in the unlabeled set. Despite its importance, the impact of labeled data selection has not been explored in the category discovery literature to date. We show that changing the labeled data can significantly impact discovery performance. Motivated by this, we propose two new approaches for automatically selecting the most suitable labeled data based on the similarity between the labeled and unlabeled data. Our observation is that, unlike in conventional supervised transfer learning, the best labeled is neither too similar, nor too dissimilar, to the unlabeled categories. Our resulting approaches obtains state-of-the-art discovery performance across a range of challenging fine-grained benchmark datasets.