 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKU-ISPL Language Recognition System for NIST 2015 i-Vector Machine Learning Challenge
Paper and Code
Sep 21, 2016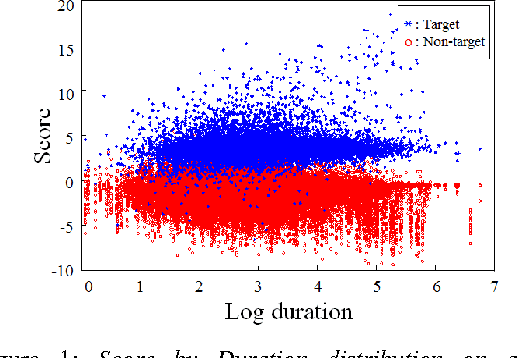

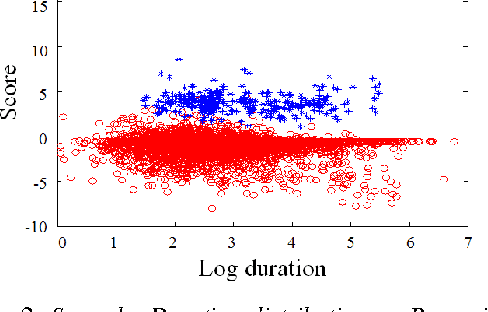
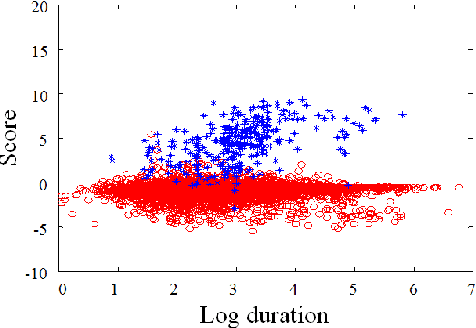
In language recognition, the task of rejecting/differentiating closely spaced versus acoustically far spaced languages remains a major challenge. For confusable closely spaced languages, the system needs longer input test duration material to obtain sufficient information to distinguish between languages. Alternatively, if languages are distinct and not acoustically/linguistically similar to others, duration is not a sufficient remedy. The solution proposed here is to explore duration distribution analysis for near/far languages based on the Language Recognition i-Vector Machine Learning Challenge 2015 (LRiMLC15) database. Using this knowledge, we propose a likelihood ratio based fusion approach that leveraged both score and duration information. The experimental results show that the use of duration and score fusion improves language recognition performance by 5% relative in LRiMLC15 cost.