 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKey Instance Selection for Unsupervised Video Object Segmentation
Paper and Code
Jul 26, 2019


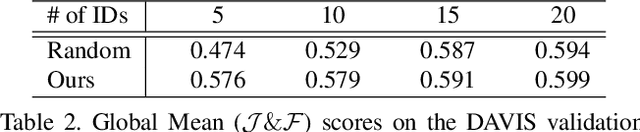
This paper proposes key instance selection based on video saliency covering objectness and dynamics for unsupervised video object segmentation (UVOS). Our method takes frames sequentially and extracts object proposals with corresponding masks for each frame. We link objects according to their similarity until the M-th frame and then assign them unique IDs (i.e., instances). Similarity measure takes into account multiple properties such as ReID descriptor, expected trajectory, and semantic co-segmentation result. After M-th frame, we select K IDs based on video saliency and frequency of appearance; then only these key IDs are tracked through the remaining frames. Thanks to these technical contributions, our results are ranked third on the leaderboard of UVOS DAVIS challenge.