 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel Interpolation of High Dimensional Scattered Data
Paper and Code
Sep 03, 2020
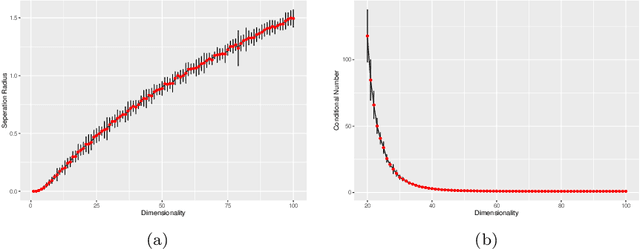
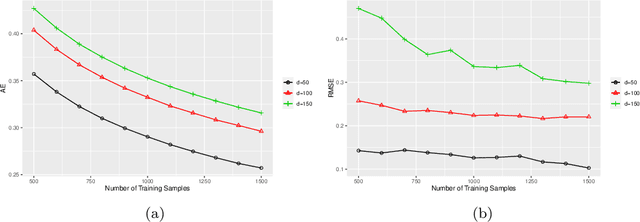
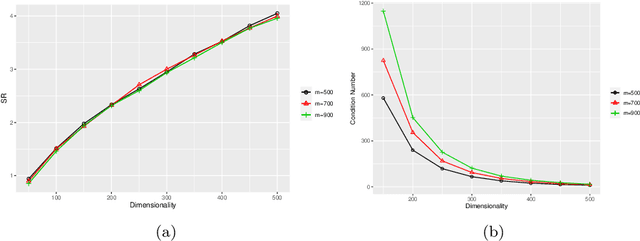
Data sites selected from modeling high-dimensional problems often appear scattered in non-paternalistic ways. Except for sporadic-clustering at some spots, they become relatively far apart as the dimension of the ambient space grows. These features defy any theoretical treatment that requires local or global quasi-uniformity of distribution of data sites. Incorporating a recently-developed application of integral operator theory in machine learning, we propose and study in the current article a new framework to analyze kernel interpolation of high dimensional data, which features bounding stochastic approximation error by a hybrid (discrete and continuous) $K$-functional tied to the spectrum of the underlying kernel matrix. Both theoretical analysis and numerical simulations show that spectra of kernel matrices are reliable and stable barometers for gauging the performance of kernel-interpolation methods for high dimensional data.