 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgek-FFNN: A priori knowledge infused Feed-forward Neural Networks
Paper and Code
Apr 24, 2017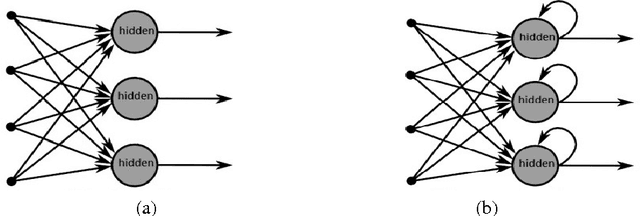
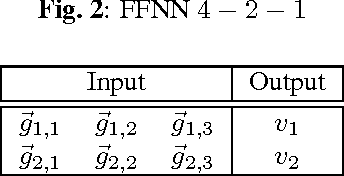
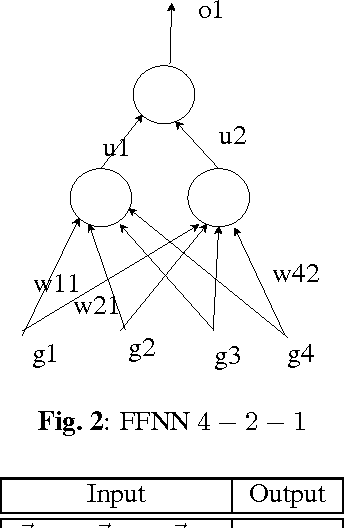

Recurrent neural network (RNN) are being extensively used over feed-forward neural networks (FFNN) because of their inherent capability to capture temporal relationships that exist in the sequential data such as speech. This aspect of RNN is advantageous especially when there is no a priori knowledge about the temporal correlations within the data. However, RNNs require large amount of data to learn these temporal correlations, limiting their advantage in low resource scenarios. It is not immediately clear (a) how a priori temporal knowledge can be used in a FFNN architecture (b) how a FFNN performs when provided with this knowledge about temporal correlations (assuming available) during training. The objective of this paper is to explore k-FFNN, namely a FFNN architecture that can incorporate the a priori knowledge of the temporal relationships within the data sequence during training and compare k-FFNN performance with RNN in a low resource scenario. We evaluate the performance of k-FFNN and RNN by extensive experimentation on MediaEval 2016 audio data ("Emotional Impact of Movies" task). Experimental results show that the performance of k-FFNN is comparable to RNN, and in some scenarios k-FFNN performs better than RNN when temporal knowledge is injected into FFNN architecture. The main contributions of this paper are (a) fusing a priori knowledge into FFNN architecture to construct a k-FFNN and (b) analyzing the performance of k-FFNN with respect to RNN for different size of training data.