 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJust Add Force for Contact-Rich Robot Policies
Paper and Code
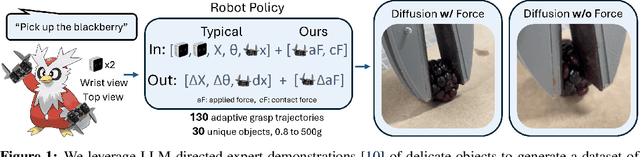
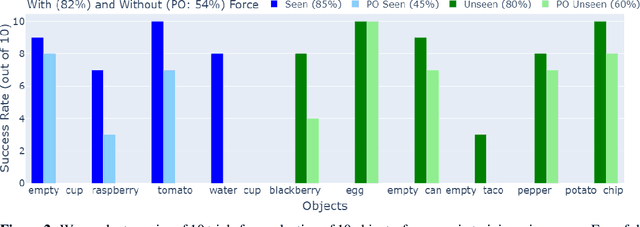
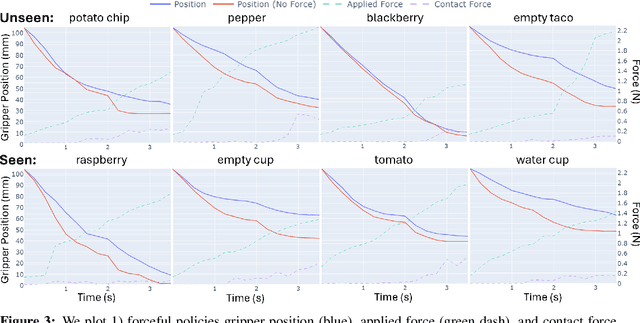
Robot trajectories used for learning end-to-end robot policies typically contain end-effector and gripper position, workspace images, and language. Policies learned from such trajectories are unsuitable for delicate grasping, which require tightly coupled and precise gripper force and gripper position. We collect and make publically available 130 trajectories with force feedback of successful grasps on 30 unique objects. Our current-based method for sensing force, albeit noisy, is gripper-agnostic and requires no additional hardware. We train and evaluate two diffusion policies: one with (forceful) the collected force feedback and one without (position-only). We find that forceful policies are superior to position-only policies for delicate grasping and are able to generalize to unseen delicate objects, while reducing grasp policy latency by near 4x, relative to LLM-based methods. With our promising results on limited data, we hope to signal to others to consider investing in collecting force and other such tactile information in new datasets, enabling more robust, contact-rich manipulation in future robot foundation models. Our data, code, models, and videos are viewable at https://justaddforce.github.io/.