 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Surgical Gesture and Task Classification with Multi-Task and Multimodal Learning
Paper and Code
May 02, 2018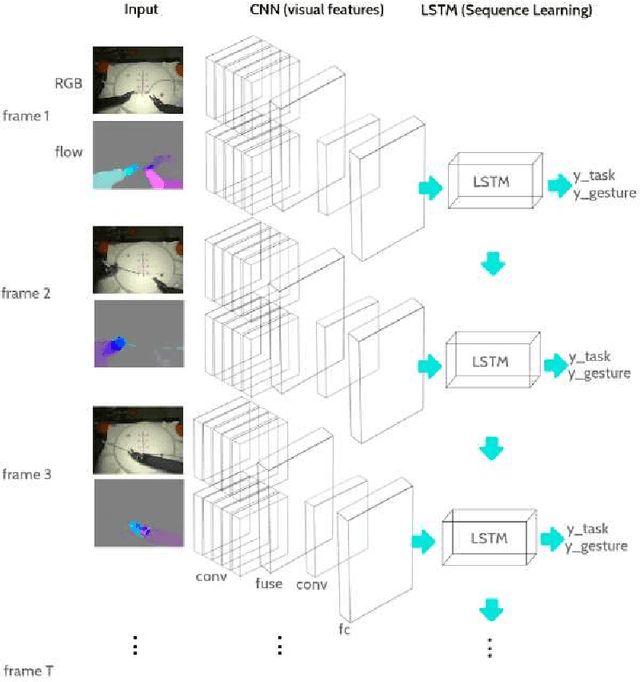
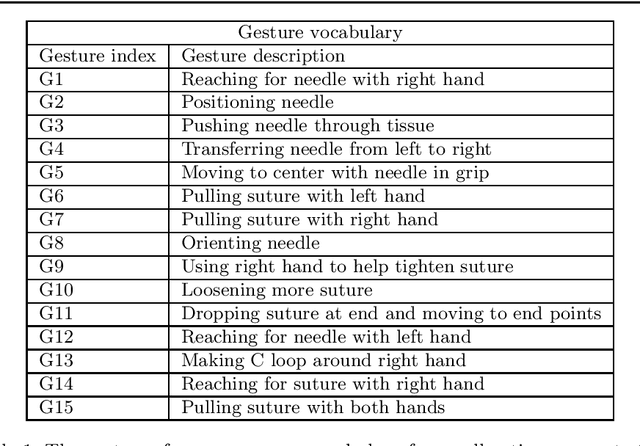

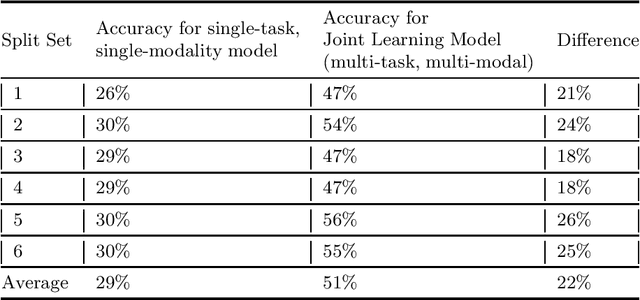
We propose a novel multi-modal and multi-task architecture for simultaneous low level gesture and surgical task classification in Robot Assisted Surgery (RAS) videos.Our end-to-end architecture is based on the principles of a long short-term memory network (LSTM) that jointly learns temporal dynamics on rich representations of visual and motion features, while simultaneously classifying activities of low-level gestures and surgical tasks. Our experimental results show that our approach is superior compared to an ar- chitecture that classifies the gestures and surgical tasks separately on visual cues and motion cues respectively. We train our model on a fixed random set of 1200 gesture video segments and use the rest 422 for testing. This results in around 42,000 gesture frames sampled for training and 14,500 for testing. For a 6 split experimentation, while the conventional approach reaches an Average Precision (AP) of only 29% (29.13%), our architecture reaches an AP of 51% (50.83%) for 3 tasks and 14 possible gesture labels, resulting in an improvement of 22% (21.7%). Our architecture learns temporal dynamics on rich representations of visual and motion features that compliment each other for classification of low-level gestures and surgical tasks. Its multi-task learning nature makes use of learned joint re- lationships and combinations of shared and task-specific representations. While benchmark studies focus on recognizing gestures that take place under specific tasks, we focus on recognizing common gestures that reoccur across different tasks and settings and significantly perform better compared to conventional architectures.