 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsometric Neural Machine Translation using Phoneme Count Ratio Reward-based Reinforcement Learning
Paper and Code
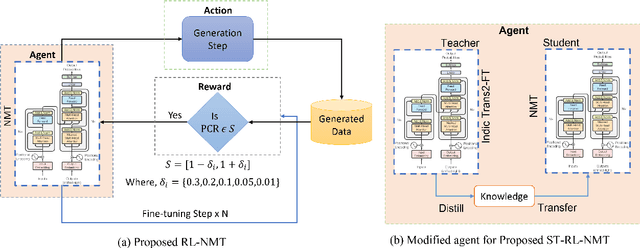



Traditional Automatic Video Dubbing (AVD) pipeline consists of three key modules, namely, Automatic Speech Recognition (ASR), Neural Machine Translation (NMT), and Text-to-Speech (TTS). Within AVD pipelines, isometric-NMT algorithms are employed to regulate the length of the synthesized output text. This is done to guarantee synchronization with respect to the alignment of video and audio subsequent to the dubbing process. Previous approaches have focused on aligning the number of characters and words in the source and target language texts of Machine Translation models. However, our approach aims to align the number of phonemes instead, as they are closely associated with speech duration. In this paper, we present the development of an isometric NMT system using Reinforcement Learning (RL), with a focus on optimizing the alignment of phoneme counts in the source and target language sentence pairs. To evaluate our models, we propose the Phoneme Count Compliance (PCC) score, which is a measure of length compliance. Our approach demonstrates a substantial improvement of approximately 36% in the PCC score compared to the state-of-the-art models when applied to English-Hindi language pairs. Moreover, we propose a student-teacher architecture within the framework of our RL approach to maintain a trade-off between the phoneme count and translation quality.